Notes de version 1.12

Contents
The Microsoft .NET Framework Runtime version 4.8 must be installed on the IIS server running Collections (after which the server needs to be rebooted). Ask your system administrator if this still needs to be done.
New options and functions for Axiell Collections make further use of Adlib for Windows impossible
Some of the new functionality introduced in this version and previous versions of Collections requires to be set up by your application manager (as indicated per topic in the various Collections release notes), using new options in Axiell Designer. Since development of Adlib for Windows has ceased quite a long time ago, these new options are not supported by Adlib for Windows. Even if Adlib would ignore the relevant option, you could no longer reliably work in Adlib too, so altered applications using Collections-only functionality should never be opened in Adlib again.
New Collections online Help
The current English version of the Collections online Help you see before you, has been revamped and moved to a different URL: http://help.collections.axiell.com/, although it won't contain these release notes just yet and is still a work in progress. To have your Collections application open that new version automatically, your application manager will have to make a simple change to the Collections settings.xml file: almost at the top of that file, the <Help>http://documentation.axiell.com/alm/collections/</Help> reference (which points to the current version) should then be replaced by <Help>http://help.collections.axiell.com/</Help>. After recycling the application pool, clicking the Help button in the main toolbar on the left, will open the new Help version if you're connected to the internet.
Note that the new version will only be present in English for now. If you make the change above and you click the Help button, you will always be redirected to that English version, regardless of the interface language currently active in Collections. Since the current Collections online Help is available in Danish and French too, users in those language regions are probably better off leaving the <Help> setting as it is, as this will still allow you to use the Help in your own language.
2022-02-03: release Axiell Collections 1.12.1
Today we release Axiell Collections 1.12.1, offering the bug fixes and new functionality described below.
Bug report no. |
Short problem description |
CV1-3828 |
It was no longer possible to save changes on existing metadata relationships. |
CV1-3812 |
The import function in Collections didn't work anymore. The summary stated that a number of records was processed, but records weren't imported. |
CV1-3793 |
After adding rows in a table grid for a linked field, if you moved and edited different fields in different rows in the grid, the system would become non-responsive, i.e. when clicking on an editable field, it could take a long time before Collections allowed you to enter a value again. |
CV1-3775 |
There was a Field name 'record' not found error when using the Simple search option in the Standard search dialog. |
CV1-3773 |
A Media Viewer opened in its own window allowed the saving of displayed images from its right-click menu. |
CV1-3771 |
ADAPL did not recognize an empty HTML field as empty. |
CV1-3750 |
If a field was set to sort ascending, then saving the record did no longer sort the field. |
CV1-3747 |
In the Related records view, navigating to a set of linked records didn't work for reverse relations. |
CV1-3745 |
Sometimes there were performance issues when saving records, even simple records. |
CV1-3735 |
The Related records view didn't show relations for some records. |
CV1-3732 |
If a priref was supplied in a non-update import, it would create a second priref field. |
CV1-3707 |
The vertical placement of the page navigation bar beneath the Result set was not consistent. |
CV1-3702 |
The Simple search tool at the top of the Gallery view didn't work. |
CV1-3648 |
A FACS READ returned &E=7 in a situation where the FACS database contained a single record with priref > 1. |
CV1-3553 |
The logon history did not record the logon name for failed logons. |
CV1-3498 |
Under certain circumstances, it was not possible to delete your own saved search. |
CV1-3405 |
Less-than/greater-than searches were not available for fields with an alphanumeric index. |
CV1-3201 |
Numeric fields would always display too narrow. |
CV1-3106 |
Context fields did not display translated terms when the data language was changed. |
CV1-2944 |
For adapl-only output formats, when run in debug mode, for some records &I was missing from the debug XML file. |
CV1-2879 |
For adapl-only output formats, when printing multiple records, the PDF output sometimes got blocked by the browser (Chrome/Edge). |
CV1-1601 |
Not all mandatory fields on a screen had a pink background when empty. |
CV1-1146 |
A task was aborted when it wanted to lock a record which was already locked. |
2022-01-04: viewing the executed search statement in the Result set status bar
Collections 1.12.1 shows the executed search statement in the status bar at the bottom of the Result set view. This is good reminder of the search which led to the current search result. Since there are four ways of searching, each one displays the search statement slightly differently.

A Standard search for example displays the field tag of the field you have searched on, not the field name (The Object number access point is associated with the field tag IN):

An Advanced search on the other hand, is displayed as it was entered. So the following search statement:

would show up in the status bar as follows:

If the Result set displays the contents of a saved search, the status bar will only show the number of the selected saved search with the term pointer in front of it (an alternative term for saved search is pointer file).

A field specific search via the Search option in the Result set context toolbar, like the following:

will result in a status bar search statement similar to one resulting from a Standard search:

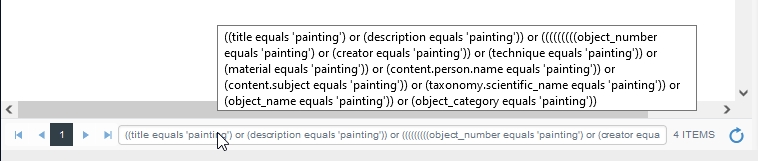
A simple search, executed via the same Search option in the Result set context toolbar, for example:

results in a rather long status bar search statement because this is actually a combined search on several different fields simultaneously (which is exactly why it's an such an easy way to find records). If you hover the mouse cursor over the partially displayed search statement, a tooltip will show the full search statement so this is a good way to find out which fields are actually being searched with your simple search option (as this differs per data source and per application):
Note that if you use the Related records view to jump to another record, you'll notice that the contents of the Result set changes to this other record as well. The search which has been executed implicitly to display that new Result set is nothing more than a search on the record number of the selected record and will be shown like this:

2021-12-10: release Axiell Collections 1.12
Today we release Axiell Collections 1.12, offering the bug fixes and new functionality described below.
2021-11-16: release notes Axiell Collections 1.12
Bug report no. |
Short problem description |
CV1-3650 |
The HTML title attribute was often used for texts meant for screen readers, but that was unreliable. |
CV1-3645 |
In a multilingual linked field the fixed domain was not added to the linked record. |
CV1-3637 |
A saved search did not work anymore if the sort option was not used with the English field name or the tag. |
CV1-3627 |
It was not possible to create a new record in the Serials module because the mandatory Title field was automatically emptied before saving. |
CV1-3626 |
In a new record the source title field was emptied when the field was left. |
CV1-3612 |
Keyboard users and screen reader users could not move through to the next elements on the Standard search form using Tab, once the focus was on a date picker field. |
CV1-3595 |
The IP address of users was visible in the Active sessions window for application admins, which was not necessary and a little too much information. |
CV1-3594 |
Via the returned error message displayed during failed authentication attempts, the Collections login functionality revealed whether or not a user existed, which might pose a security risk. |
CV1-3592 |
Collections did not properly regenerate sessionID tokens upon a successful login and logout, posing a potential security risk. |
CV1-3539 |
Full dates stored in metadata tables either did not display or caused an error when opening a record. |
CV1-3538 |
The ADAPL FORMATFIELD function didn't port the current record priref to the folderID in the storage path for an application field, causing an incorrect path for a document to be stored in an entreprise environment. |
CV1-3527 |
An after-field adapl which was supposed to clear certain fields after creating some new records, did not directly clear those fields: only when saving the record or when deselecting the marked checkbox that started the adapl, were the fields actually cleared. |
CV1-3517 |
A simple search could be slow to load the Result set. |
CV1-3516 |
Result set loading performance could be slow when moving between pages. |
CV1-3508 |
Performing a hierarchical search on the lowest level of a hierarchy generated an error. |
CV1-3499 |
In specific cases, related to the presence of metadata tables, deletion of a record would generate an error message "Invalid column name 'term'...". |
CV1-3495 |
A warning on an invalid date field value resulted in an empty red message box. |
CV1-3492 |
Collections allowed you to save a circular relation within a thesaurus hierarchy. |
CV1-3488 |
After adding a new row to a linked table grid, it was not possible to see it or scroll down to the new row. |
CV1-3483 |
A filled-in enumerative field in edit mode displayed the neutral value instead of the display value. |
CV1-3482 |
A date value got cleared when the date field was populated the second time by an after-field adapl. |
CV1-3480 |
In a multilingual application, a record template didn't save any values in multilingual fields. |
CV1-3479 |
Linking a large number of object records to an outgoing loans record took a very long time. |
CV1-3478 |
Issue with conditional suppression in a numeric field: field was not hidden when it had to. |
CV1-3477 |
The Restore inheritance function did not work on linked fields. |
CV1-3476 |
When a date field was populated via a storage adapl, then the date value saved in the SQL table was in the format of 'dd/mm/yyyy', instead of the ISO date format. |
CV1-3475 |
A previous search on an enumerative field was seemingly remembered by Collections because the search key was displayed on the Standard tab, but when executing the dislayed search again, the search was executed without the enumerative field search key. |
CV1-3474 |
Default values set for logical fields were not filled in in newly imported records. |
CV1-3471 |
If screen texts (on the User interface texts field properties tab in an .inf) had been set for a field, then the screen text in the current user-interface language appeared as the field name in the field list in the Advanced search too, but you could not search on this field's screen name and you didn't know the real field name. An Invalid search expression: Field name '<selected field screen text>' not found in '<database>', dataset '<dataset>' would be displayed when trying to execute the search. |
CV1-3467 |
Error messages from storage adapls in linked database were not visible in the error overview after an executed task. |
CV1-3466 |
Inherited field values were not accessible in a storage adapl. |
CV1-3465 |
Certain metadata fields didn't display. |
CV1-3440 |
Searching with a fixed query as method on a non-preferred term returned no records. |
CV1-3427 |
SqlDateTime overflow when trying to set a schedule for a saved search. |
CV1-3422 |
ADAPL errorm severity codes were not handled properly anymore, causing a code 0 or 1 to be treated as a code 2. |
CV1-3410 |
A field condition only worked on the first occurrence of a repeated field. Other occurrences were ignored. |
CV1-3387 |
Initial column widths in record detail table grids were defaults for some fields types but other fields turned out very narrow by default. |
CV1-3374 |
Adding a new row after entering a value in a linked field with a selection list format string emptied the linked field. |
Cv1-3365 |
Tabbing from the name.type field after adding a new occurrence with Ctrl+Enter did not take the user to the new occurrence but to another field. |
CV1-3359 |
Searching for all records in Collections 1.11.1 was substantially slower than in 1.9.5. |
CV1-3349 |
Navigating to a related record in another dataset didn't display the correct Result set and detail screens. Clicking on a related record in the Record details view was not designed to move to another dataset. Viewing the relations in the Related records view does offer this feature. |
CV1-3342 |
The Hierarchy browser only displayed the first related record for all records but the top-level record, and then also didn't use the Hierarchy browser Format string. |
CV1-3326 |
A table grid in edit mode didn't show all the rows when there were lots of them. |
CV1-3324 |
Ater entering a text, not a date, in a date field on the Standard search form and clicking Find, a Bad request error came up, instead of a proper error message. |
CV1-3269 |
Advanced searching on valid dates (as displayed in the records) did often not result in any found records. |
CV1-3265 |
The Hierarchy browser did not synchronize with the Result set after every search. |
CV1-3261 |
Sorting in the Hierarchy browser could be wrong when the number of nodes per request was lower than the number of narrower term field occurrences. |
CV1-3241 |
An after-field adapl wasn't firing when leaving the relevant field if it was in a table grid. |
CV1-3196 |
Advanced search using the WHEN operator did not work. |
CV1-3192 |
Printing an indented text with an adapl-only output format only worked if also something was printed at position 1 of that line. |
CV1-3191 |
The OUTPUT PAGE command in ADAPL didn't create a new page. |
CV1-3190 |
The ONSOP ADAPL command collects data to print in the header, but it collected too much data and printed it all in one line. |
CV1-3128 |
The &L system variable in ADAPL was not recognized by Collections. |
CV1-2933 |
Moving existing collect records between internal and external datasets took several minutes, and when the task had finished, the records hadn't actually been moved. |
CV1-2764 |
If a field was used in the Result set grouping bar and you dropped a marked record (to remove it from the Result set), then the grouping disappeared and the record was not dropped from the list. |
CV1-2649 |
When in the Search and replace window the With field was left empty, then the content of the field was not deleted when it should have been. |
CV1-2621 |
If you used the Keep marked records or Drop marked records functions and then sorted on the reduced Result set, the unwanted records came back and reverted the record list to the previous one. |
CV1-2509 |
Clicking different records in hierarchy browser created a confusing mismatch of highlighted records in the Result set, the Gallery view and the Record details view. |
CV1-2427 |
An advanced search with WHEN NOT gave unexpected results. |
CV1-2362 |
A Standard search on a linked field with a non-unique key index did not search on the selected record from the Find data for the field window, but on all homonyms of the key. |
CV1-1997 |
Adapl errorm message was not displayed when using the Axiell Move function to link items. |
2021-11-26: Restoring earlier deleted records
A long awaited function is now part of Collections 1.12: the ability to restore earlier deleted records. Sometimes you accidentally or purposefully delete a record that in retrospect shouldn't have been deleted. Now there's a way to get it back, via your application administrator.
If you're an application user with the $ADMIN role and if journaling has been set up for your application (via the Journal field changes = Record history (Collections) setting for your .inf database definitions) you'll get to see a new option in the main menu on the left, called Maintenance, with currently only one option: Journal maintenance.

It doesn't matter if you're on the Collections home page or whether you're elsewhere in Collections, you can always open this tool. Click Journal maintenance to open a window with the same title.

The left window pane shows all earlier deleted records in the currently selected data source (deleted since Collections journaling is active in your application, that is). These are records that appear in the database journal but not in the database table itself (thus deleted records). So first select the data source in which you'd like to see the deleted records, from the drop-down list in the top left corner: you can select any data source regardless of any data source you were working in before you opened the Journal maintenance window. Of the listed deleted records you will see the record number (priref), the user name of the user who originally created the record and the original creation date. You cannot search the list on record contents but you can set a filter per column to limit the list. Just click the filter icon in the desired column header and set your filter condition.
Once you select a record by clicking it, it's details will be shown in the right window pane*, one row per field occurrence, between [] you'll find the occurrence number. Contents of linked fields (indicated with a chain icon in the second column) are not resolved: this means that you only get to see the record number of the linked record, not the resolved value you normally see in a linked field. But if a deleted record contains enough data, the data shown should be enough to conclude if you've found the right record to restore.

The window is resizable by dragging its borders (the window panes by dragging the splitter in the middle) and the width of the columns can be changed too by dragging the separator between two column headers. You can sort on any column in the left or right window pane (except the link column) by clicking the column header one or more times to get the sorting you want. You can close the window with the Cancel button.
You can restore one or more marked deleted records at the same time. Just select the desired records using Ctrl+clicking the desired rows, by clicking the individual checkboxes or by Shift+clicking to select a range. Note that once you click a row (not a checkbox) without holding down Ctrl or Shift, any greater selection will be undone and only the currently clicked record will be selected. The right window pane will only update when you select a single record. When you select extra records, the right window pane will keep displaying the first selected record.
When you're happy with your selection, click the Restore icon above the list to restore the deleted records.
![]()
The restoring will start immediately and will show a progress bar. After the process has finished the progress bar dialog will disappear and the record list will be updated to reflect the new situation.
Restored deleted records won't be visible in this list anymore: you should be able to find them in the relevant data source with an appropriate search. The restored records will have their original record number (which can't interfere with existing record numbers).
Just before new or existing records are stored, usually a so-called before-storage procedure (adapl) is executed in the background to check entered data, to add management details and such. However, such a before-storage procedure won't run for records being restored, so a record is restored exactly the way it was when it was deleted.
* In rare cases, clicking a record won't show its details in the right window pane: this is because journal entries haven't always been created in a consistent way, so a mismatch would then result in an empty right window pane here. Such records might not restore all right.
2021-11-25: the old Filter button has been renamed to Extend search
The old Filter button in the Find data for the field window to search more specificly on other fields than just the lookup field for the current linked field, has been renamed to Extend search to better reflect its function and to avoid confusion with the new 1.12 filter functionality.

2021-11-22: new SDI implementation with background service
In Collections, SDI (Selective Dissemination of Information) is already accessible via the possibility to schedule the rerunning of saved searches. For a selected saved search In the Manage saved searches window, you can click the Schedule button to open the Saved search schedule window in which you may set up an SDI schedule aka profile. In the background, a so-called SDI server handles the rerunning of the saved searches and the e-mailing or printing. Of that SDI server now an alternative implementation is available. If that new version has been set up by your application manager, you'll find that the Printer destination option on the Destinations tab is now a user-friendly drop-down from which you can easily pick the desired printer for the SDI profile (if it is meant for printing of course). Also, you'll see a new Run now button: use it at will to test your SDI profile right now, ignoring everything you've set on the Schedule tab, just to see if printing or e-mailing works out and if the search result is as expected.

Any Comments provided on the General tab will be used for the e-mail body in cases where a report has to be sent as an attachment and thus no body is present. If you set an XSLT (producing HTML) in the Format option on the General tab and still mark the Plain text radio button on the Destinations tab, the Comments will end up in the body and the generated HTML file (named after the Subject of the saved search schedule) will be attached to the e-mail; mark HTML instead to have the generated HTML inserted in the e-mail body itself.
In the new implementation, the Limit option on the General tab is not active yet.
Moreover, once you save a new SDI profile, it will be listed with any earlier executed import jobs in the Scheduled tasks window which opens with the Schedule button in the main Collections menu on the left. And whenever the schedule is executed (by hand or automatically), the status of the listed task in the Scheduled tasks window will change accordingly. The Subject provided for the saved search schedule will be shown as the Description of the task in the Scheduled tasks window: if no subject was provided then the saved search Title will be used.
If your application manager set up this new SDI implementation for Collections 1.12 while you were already using SDI then your old SDI profiles can be used by the new service as well: you just have to make some trivial change (change something, click OK, change it back, click OK) to each of those old SDI profiles to have the new functionality pick them up and activate them for processing. For SDI profiles meant for printing, be sure to select the desired printer from the drop-down list (again). The previously set printer name may not be visible anymore or not compatible with any of the printer names in the drop-down list, so select the desired printer again. Use Run now to see if the adjusted profile still works. In the Scheduled tasks window you can check if the old SDI profiles are now included in the list.
It may at first seem odd that SDI tasks and background import jobs are listed in the same window, but it is one and the same scheduler service that handles both types of jobs in the background, possibly even using a different (hidden) Collections installation on a different server so that processor/memory heavy tasks like large import jobs or large print tasks can be executed without performance penalty for Collections users.
Note that for this new implementation of the SDI background service the path provided in the Format option on the General tab of the Saved search schedule window (pointing to an adapl or XSLT stylesheet to layout the output) has to be relative to the folder containing the Collections application .pbk file, e.g. ..\xslt\mytemplate.xsl. Ask your application manager which folder holds the relevant file and what then the path for the Format option should be.
2021-11-20: deleting import jobs and SDI tasks which were run in the background (scheduled tasks)
After you've run an import job in the background it is listed in the Scheduled tasks window. This list won't be cleaned up automatically so when you run import jobs in the background regularly, the list may get rather long. Therefore, now a Delete button has been added to delete earlier executed import jobs from this list, if you no longer need that information for future reference. You can delete more than one listed job at the same time, by selecting all the jobs you wish to be deleted (by Ctrl+clicking the desired jobs or by Shift+clicking to select a range of jobs) and then clicking the Delete button. Any SDI background tasks (see topic above) are also visible in this window: you can delete those listings too if you want, that won't delete the actual SDI profiles but just the historical reference to some status change in this list.
Note that you cannot delete (or cancel) an import job that is still running, so only try deleting jobs with a status other than Running.

Also note that the functionality to run import jobs in the background is only available in Collections once specifically set up by your application manager.
2021-11-19: Spanish system texts added
Spanish system texts (labels of functions) have been added to Collections 1.12. These Spanish interface texts only become available once your application manager has activated the Spanish interface language.
Note that application texts (field labels, screen titles and such) are not included in Collections releases.
2021-11-17: Collections browser tab headers now showing distinguishing information
When Collections was opened in a browser, it always displayed just the title of the application in the browser tab. However, since Collections can now be opened in multiple browser tabs, it could be confusing to screen reader users to find the same title in every tab header. Therefore, Collections 1.12 now adds the currently opened data source name and the record number of the currently selected record to the application title in the tab header, to better distinguish the different tabs. No setup in Designer is required.

If you can't read the text visually because it's too long for the tab, then just hover the mouse cursor over the tab to have the full text displayed in a tooltip. For all users this is also a quick way to find out what the record number of the currently selected record is.
2021-11-16: minimize/maximize main menu icon and tooltip improved
The ![]() icon to minimize or maximize the Collections main menu (the vertical toolbar on the left) has changed to an arrow icon because the old icon looked too much like other icons with a different function and its tooltip has been improved to aid screen reader users: Minimize the Main menu. Display icons only. in maximized state and Maximize the Main menu. Display icons and labels. in minimized state.
icon to minimize or maximize the Collections main menu (the vertical toolbar on the left) has changed to an arrow icon because the old icon looked too much like other icons with a different function and its tooltip has been improved to aid screen reader users: Minimize the Main menu. Display icons only. in maximized state and Maximize the Main menu. Display icons and labels. in minimized state.

2021-11-03: download button for image and application fields conditionally hidden
From Designer 7.7.4 and Collections 1.12, application managers have the possibility to disable the download button next to image and application fields conditionally, so that maybe only certain users can download the images or files registered in that field in the opened record. A condition may also specify that the presence of the download button depends on values in some other fields in the record. So if a certain image or application field sometimes (or for certain users) does have download buttons next to its occurrences while at other times (or for other users) it doesn't, then it is likely that a disable condition has been set for the field.
Note that the download button can be disabled unconditionally for a field too.
2021-10-11: visibility of previous search improved
After performing a search on the Standard tab of the Search <data source> dialog, Collections will remember the entered search key(s) for next time you open this dialog. However, if you just entered an asterisk or another short key, maybe at the bottom of the list of fields to search, you could easily overlook that value and perform a new search without being aware that the old value was included in that search as well. Therefore, in Collections 1.12, entry boxes with a previously entered search key are now displayed with a bold black border, to make it easier for you to notice the old search key. You may of course remove or keep the old search key, as needed for the new search.

2021-09-22: searching and working within your own set of records
From Collections 1.12, you can specify a so-called filter, a search query per data source, which will be added to every other query automatically so that you will always be searching and working within the set of records that is relevant to you. For example, if you're working with model application 5.0, suppose it is your responsibility to manage all object records with management status internal and object category ceramics and you don't need to concern yourself with other records. You can of course simply perform this search on the Standard search tab, but not in Simple search and if you like using the Advanced search then you must remember to include management_status = "internal" and object_category = "ceramics" in every search for more specific records, which is cumbersome.
To solve that problem a new Filter button has been added to the Standard search tab.

Click it to open the Search filters form, similar to the Standard search tab itself: it offers the same access points (which can be selected via the Settings button) and Boolean options for combining the access points on this form. Just put together the search query you'll want any other regular search via Simple search, Standard, Advanced or Saved searches to be combined with (implicitly combined via a Boolean AND) and click OK. To stick with our example, you would fill the Search filters form like this:

From now on, this filter is active for all other search queries until you change or empty the filter by editing it from the Standard search tab again. (Emptying a filter deactivates/deletes it.) To notify you of the active filter, the Standard and Advanced search tabs display a filter notification like so:


Plus, after performing an actual search with an activated filter, the title bar of the Collections application will display a filter icon next to the data source name. If you hover the mouse cursor over the icon, it will show the advanced search statement that is used as the filter.

So, for example, if you now use the Advanced search and search for all records, you won't actually find all available records in this data source but only "all" records which also have a management status internal and object category ceramics. Similarly will any Simple search from the Result set context toolbar be limited to internal and ceramics and the filter statement will also automatically be added to any Advanced search you enter. So an Advanced search like object_number = "CER-001*" will actually be executed as (object_number = "CER-001*") and (ms="INTERNAL" and OC="ceramics").
.jpg)
If you save such a set as a saved search, the whole search statement including the filter, will be stored. Having said that, if you open any saved search, the currently active filter will still be applied (even if it's already included in the saved search statement). The applied filter has consequences for the number of records that will actually be opened when you show a saved search in the Result set, because a saved search (whether it's a saved search statement or a saved selection of record numbers) which has been saved without the currently active filter may originally contain or result in more records than with the current filter applied. The Hits indicator behind a saved search always indicates the original number of found records. But if you open the saved search and a currently active filter is applied, you might see fewer records or even none.
Filters will be remembered per user and data source, so next time you open Collections, any previously activated filters will still be active.
2021-09-14: combinations of sets in advanced search now displayed as full search statements in the history
When, in the Advanced search, you combine earlier executed search statements via their set numbers, like set 1 or set 2, Collections always included exactly this search statement in Set(s) box of the history of executed search statements. Since it is much more user-friendly to translate it to the full search statement, so the you don't have to remember what you've actually searched on, that has been changed in Collections 1.12. After executing a search like set 1 or set 2, now the full translated search statement (containing the original search statements) is now displayed in the Set(s) box.
So suppose you've executed two searches, one searching for object name table and one for object name chair. They are listed as sets 1 and 2 in the Set(s) list. Now you enter the combined search set 1 or set 2.

After executing this search, the Search statement box still displays what you typed, but the new (third) set in the Set(s) list now displays the full search statement, which is more informative.

Note that a search statement which includes a reference to a set may have a different search result than a search statement without such a reference, if relevant records have been changed in the meantime. The reason is that a reference to a set means a reference to earlier found records: the original search statement which led to the referenced set is not executed again when a set is used in a new search statement.
2021-09-10: Ctrl+arrow shortcuts added for moving occurrences up or down
To move a field (group) occurrence up or down, put the cursor in the field that you wish to move, press the Ctrl key, keep it pressed down and click the up or down arrows on your keyboard to move the occurrence up or down. The other, pre-existing way of moving occurrences up or down is to use the Move field down or Move field up options of the Occurrence drop-down in the Record details view context toolbar.
2021-09-09: options to move occurrences up or down added to edit zoom screens
When you are looking at a linked record via a zoom screen and you edit that linked record there and then, you now have more control over the occurrences of repeated fields. It's was already possible to add or remove a row of a repeated field, but you now also have the options Move row up and Move row down in the Occurrence menu if the cursor is in a repeated field with multiple occurrences. It allows you to re-order the occurrences.

2021-09-09: Ctrl+Q shortcut added to remove a field occurrence
When the cursor is in a repeated field, you can now remove the current field occurrence (even the first one) by pressing the Ctrl+Q key combination on your keyboard. This might be faster than using the menu.

2021-09-09: simple search now also available on the Standard search tab
When a Simple search method has been added to a data source, it already allowed you to search multiple indexed fields at once, via the search box in the Result set context toolbar:

The method now also has the consequence that the simple search option is available on the Standard search tab when searching the relevant data source. If you can't see it yet, you must add it via the Settings button on the Standard tab first: double-click Simple search in the list of fields to move it to the list on the right. (Note that the option might be called differently in your application.)

Simple search is now an additional, quick way of searching for records, via the Standard search. The only available operator is equals, but you may combine a simple search with a search in other fields. Partial search keys have to be truncated explicitly with an asterisk.

The new addition comes in handy too when you're in a record in edit mode already and you're trying to link a record with an ID that you don't know by heart, like an object number or a library record without an ID at all. Then, when you're in the Find data for the field window for the relevant linked field, you'll probably use the Filter button at the bottom of the window to start a search for the record you want to link to, by means of some data you do know, like an object name, object category or creator or whatever. Now, instead of using the search boxes for specific fields, you can try using the Simple search box to search multiple fields at once: you may find the record you're looking for more quickly. Again, if you don't see the Simple search option on the Standard tab, you may have to add it first via the Settings button; if you can't find it in there either, then the Simple search method has probably not yet been added to the linked data source yet (which is a job for your application manager).

2021-07-14: record merging
Sometimes you may have two or more records describing the same person, the same thesaurus term or the same catalogue item or object, for example, and you'd like them merged into one, taking all the best data from those records and automatically delete the remaining ones. Collections 1.12 now offers just that functionality and gives you control over target and source record(s) and to a certain extent over which data you'd like to keep and which must be deleted. The functionality is only present if properly set up for a data source by your application manager.
Simply start by searching for the records to merge and mark all of them (at least two) in the Result set view. In the example, we'd like to merge the three marked records. Remember that of the selected records only one will remain, with your manually selected data from all the selected records, although data which is not different between the selected records will always be maintained in the target record and can't be deselected.

Then click the Merge selected records icon (Ctrl+H) in the Result set context toolbar to start the procedure (which you may still cancel at any moment):
![]()
This opens the Select record to merge into window, listing the marked records again. Now select the target record into which all selected data must end up, by simply clicking the desired record. The selected record will be highlighted with a dark grey bar. If you're not sure which record to pick you can still select it and click the Details button on the side of the window to view more data of the record. Typically you would pick the record that already has the correct unique identifier, like the proper object number for example.

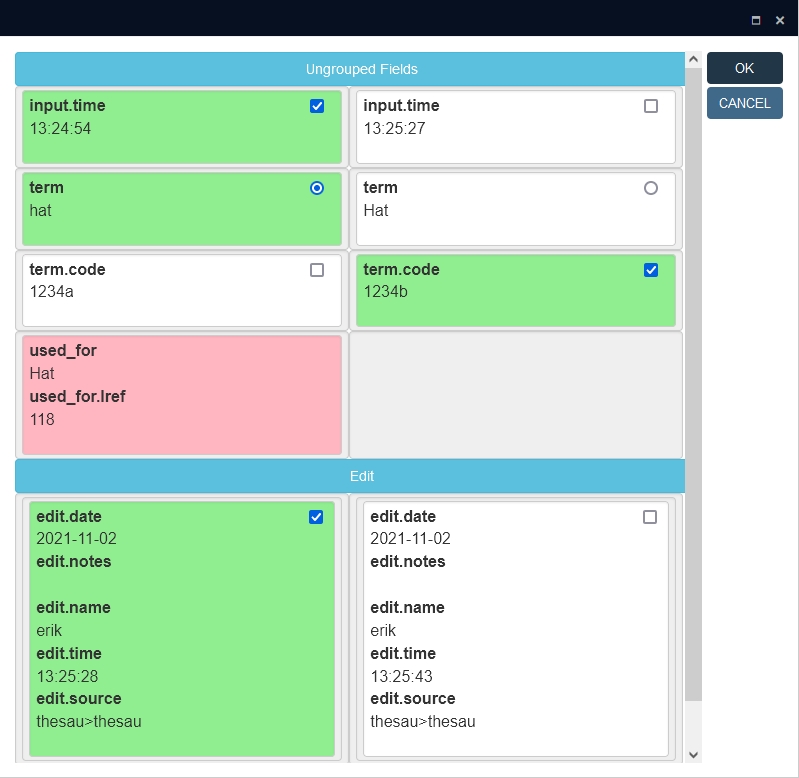
Click OK to open the actual merge window. You can see two columns: the left contains data from the target record and the right one contains data from the other selected record(s). Ungrouped fields are listed separately from grouped fields because data in grouped fields is always handled per field group occurrence, not per isolated field from the group. The data with the marked checkboxes (in green boxes) will end up as separate field occurrences in the target record, so it's up to you select or deselect the desired checkboxes. By default, all fields and field groups in the target record have already been selected, but you may deselect at will and/or select other data in the column on the right.

It is not a problem if any of the selected records are internally linked: you don't have to worry about that. In the target record, the relevant internal link will be displayed with a pink background to indicate that it will be removed automatically during the merge (so the box doesn't have a checkbox on purpose).
Click OK to perform the actual merge.
There are a few things to take into account though, before you go through with this:
| • | Of field groups, entire field group occurrences are gathered in a single selectable box, so you either maintain all data from a field group occurrence or you let it go. You can't just have the object name notes from a field group occurrence in record B and leave the object name from B behind. This could mean you end up with field group occurrences containing duplicate data (the same object name for example) which you'll have correct later by editing the resulting record manually. |
| • | Of multilingual fields, all data language values of a single field occurrence are to be selected together as one, so you either maintain all translations of the value or you let them all go. If one record has an English value B and Dutch value A in a single field occurrence and another record has a Dutch value C, then merging all values would result in the field having one occurrence with English value B and Dutch value A and a second occurrence with Dutch value C. |
| • | This functionality has no access to screen definitions, while some field properties are still only defined on screen or have only been defined properly on screen. Whether a field is mandatory for example, can only be defined on screen, so the merge window allows you to deselect all object numbers in the example shown in the screenshot below as if it wasn't a mandatory field, but fortunately the target record doesn't end up without a mandatory object number: the originally present data in the mandatory field (the object number in this case) in the target record will reappear after the merge. And if it wouldn't reappear you could still add it later. But you should be aware of mandatory fields and preferably keep them filled during the merge. Whether a field is repeatable or not, can be defined in both the database structure as well as in the screen definition. The setting in the database structure determines if multiple occurrences of the field can in principle be stored or not, while the setting for the screen field determines whether a user can actually enter or view one or more occurrences. Again, this functionality only looks at the database definition. Unfortunately, in model application 4.5.2 and older, almost all fields have always been set to repeatable in the database definition, while on the screens they have been set to non-repeatable where applicable, like for the object number field or the input details fields for example. So in these situations the merge functionality actually allows the user to create a target record with multiple occurrences of fields which shouldn't really have them: you could select multiple object numbers here or multiple input times. So here too, you should take into account which fields are meant to be non-repeatable and only select one piece of data for the target record. From model application 5.0, the repeatability setting in the database definition (.inf's) for a lot of fields now matches the screen field settings, so then the problem won't be present as much because the merge tool will then prevent you from selecting multiple occurrences of such a field by offering radio buttons for the field data, instead of checkboxes (and of radio buttons you can select only one). 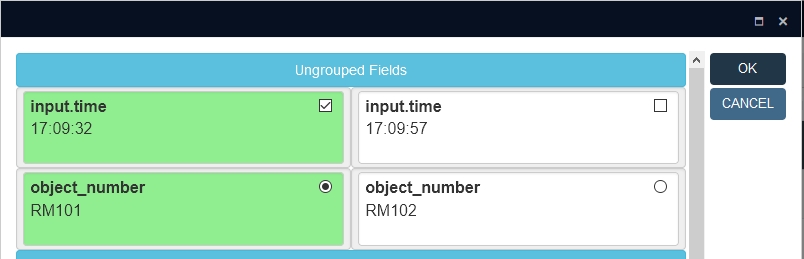 |
| • | Once you click OK, Collections will check if the record(s) to be deleted (the obsolete terms) after the merge are still in use in a linked field in any of the feedback databases. If that is the case, you'll get a warning (only mentioning one of the databases, even if there are more) and the merge won't happen.  If you still want to merge the records, you could first make the obsolete terms non-preferred terms of the final term (the destination) record. Then all references in feedback databases to the obsolete terms will automatically be updated to references to the final term. After that, the merge should succeed. |
| • | If one or some of the records you are merging have (single-sided or reverse) links to records in other databases, while the remaining record(s) do not have those links, then those links show up in the merge window as well. In the screenshot below for example, we're about to merge two object records: the one on the left is the target record and the one on the right is about to be deleted after the merge but it does have (reverse) link to an outgoing loans record which the target record does not have. You can now choose whether to include that link in the target record or not. For such a reverse link, you should realize that not including it in the target record will the delete the reverse link in the outgoing loan record too, while if you do select the reverse link to the loan record, then the target record of merge will take over the link and the outgoing loan record will be changed to link to the target record instead of to the obsolete object record. |