Release notes 7.9

Contents
Below you'll find a brief overview of new functionality implemented in Axiell Designer 7.9.0, including links to more information.
Backwards compatibility
Using new (Collections-only) Designer settings in your application and database definitions will always break compatibility with older versions of Designer and Collections and other Axiell software* using the same BaseAPI, although removing those new settings will often restore that compatibility under the condition that the SQL table structures haven't changed because of those settings: if the SQL table structures have changed too, then a SQL database backup from before that change is required as well to go back to the previous state. The Designer release notes always note the compatible version of Designer and Collections, but this applies to below list of other Axiell software too. For a full list of compatibility issues through the different versions of Designer and Collections, see the Axiell Designer compatibility topic. The Axiell software which needs to be updated to the latest version once new Designer settings have been applied (only if you have a license for that software of course) is the following: Collections, AdMove server, Workflow client, Ingest, WebAPI, SDK, AnalyzeData, Migration, ConvertInternalLinks, IndexCheck, InternalLinkCheck, LinkRefCheck, RemoveLanguageFromData, RemoveTagsFromData, DBtool and ValidateDatabase.
New options and functions for Axiell Collections make further use of Adlib for Windows impossible
New settings in Axiell Designer pertain only to applications run within an Axiell Collections environment. If such new settings are applied, then the resulting application can no longer (reliably) be opened in Adlib for Windows. Since development of Adlib for Windows has ceased quite a long time ago, these new options are not supported by Adlib for Windows. Even if Adlib would ignore the relevant option, you could no longer reliably work in Adlib too, so altered applications using Collections-only functionality should never be opened in Adlib again.
Contents
(Natural language) period-to-dates conversion
Writing the response of an OPENURL call to a file
Improving searchability on values with punctuation or diacritical characters in full text databases
Names of previously hard-coded databases now configurable
Quickly accessing the stored version of the currently edited record in ADAPL
Journalling data changes in a metadata database
A validation list for fixed domains
Importtool.exe: a new import tool supporting all current database index types
2022-10-28: release notes Axiell Designer 7.9
The following bug fixes for Designer 7.9 and new functionality for Axiell Collections version 1.15 have been implemented:
Bug report no. |
Short problem description |
CV1-4291 |
If the request.inf database name was changed to something else, clicking the mission items link button in the Axiell Move dashboard in Collections resulted in an error, because request.inf was the mandatory name. Solved with new functionality to configure previously hard-coded database names: please see the relevant new functionality paragraph below. |
AX-398 |
The Application tester reported missing adapl files for 'Normal page' ADAPL output jobs as errors instead of warnings. |
AX-394 |
The Application tester did not report on duplicate tags and field names in a database. |
AX-393 |
The Application tester reported missing index tables that don't (need to) exist because of full text indexing. |
AX-390 |
Trying to copy a data source in a .pbk produced an unhandled exception. |
AX-388 |
Designer tried to lock the Designer settings.xml file for writing, without proper reason. |
AX-387 |
Clearing all databases reported errors on dropping the application_settings SQL table, then still deleted it, but did not recreate it. |
AX-382 |
Sometimes the Default values tab for fields were cleared and there was no possibility of adding the defaults back. |
AX-381 |
Some Designer actions took a long time to perform, like changing SQL database properties in a database definition or opening the \data or application .pbk folder. |
AX-328 |
The Application tester did not report a field that is defined as an HTML field on screen, but has no corresponding field definition. |
AX-262 |
XML documentation didn't report the Default type when no default values were set. |
AX-259 |
The Application tester didn't report on default text values in a field with Default type not set to "Value". |
AX-257 |
The Application tester reported "hidden" linked field definitions in a non-linked field as warnings instead of errors. |
AX-256 |
The Application tester didn't report on enumeration values in a non-enumerative field. |
AX-210 |
The Application tester didn't report on an index tag without a matching field tag definition. |
AX-39 |
The Application tester didn't report on fields having a Default Type 'Value' without having an actual value defined. |
2022-06-22: (natural language) period-to-dates conversion
Designer 7.9 and Collections 1.15 introduce a new Period field type and accompanying Period index type which allows users to enter and save date periods expressed in natural language, like "12th century", "Spring 2022", "late 2018", "Early 19th Century - 2022", "1950s" etc., in a record while the indexed values actually become date ranges in the form of real (numerical forms of) ISO start and end dates, like 1100.0101 - 1199.1231, 2022.0301 - 2022.0531, 2018.0901 - 2018.1231, 1800.0101 - 2022.1231 and 1950.0101 - 1959.1231 respectively: the user will never see these ISO dates as the entered natural language date period will be saved in the record However, when the user searches this field, he or she can only search it on complete natural language periods, like "12th century" (and years in digits), not on single words (not even truncated) from the natural language period like "century" nor on ISO dates which include months and/or days. So the search language parser converts the search key to an ISO date range too. If the user searches on a broad period, the search will not only yield that exact period but also narrower periods within that broader period. One can currently only search on a single date period, not on date period ranges. A full overview of all English natural language period elements that can be entered in a Period field (or when searching the index on this field) can be found here. Grammar files for parsing the natural language date periods into ISO dates are currently included in Collections in English (en-GB), Dutch, Danish, Welsh (cy-GB), Portuguese and Swedish. Parsing of date entry in this field depends on the current user-interface language in Collections, so while working in the Dutch UI language you'll have to enter date periods Dutch and while in English you should enter date periods in English. The same applies to searching, so in Dutch a user would search for e.g. my_period_field from "21e eeuw", while in English you search for my_period_field from "21th century", but in both scenarios you would find the same records because the index is language independent.
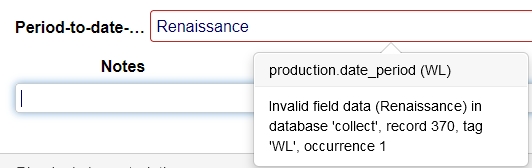
Validation takes place after changing and leaving the field. If the user enters a period that isn't recognized by the parser, a warning will be shown similar to the one below (although field name and field tag can be different) and the user will have to enter a different period.
Setup is quite easy:
| 1. | Create a new database field in the desired .inf, of Data type Period and length 100, for example: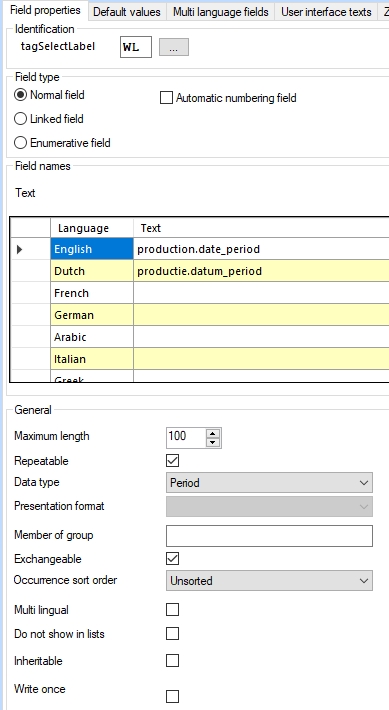 Note that Period fields cannot be multilingual as well! |
| 2. | Then create a Period index for it and reindex it, for example: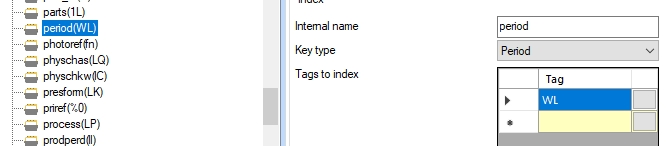 |
| 3. | And finally create a screen field for the new field on the desired screen. This can just be a Text field. For example: |
| 4. | Since the grammar of a language can be region specific you may want to configure what the region of some or all used UI languages is. A good example is the English language which has different date parsing rules for Great Britain (en-GB) and Unites States (en-US). The interface languages that must be available in your Collections installation are specified in the <Setting Key="Languages" Value="..." /> setting underneath the relevant <SessionManager> node in the settings.xml for Collections. It is not mandatory to specify a region behind a language, but it can't hurt to be specific from the start. So use e.g. <Setting Key="Languages" Value="en-GB,nl-NL" /> instead of <Setting Key="Languages" Value="en,nl" />. |
| 5. | Recycle your Collections application pool and you can test the new field. |
The record XML will hold the natural language period and the so-called culture (UI language plus region code) in which the value was entered and successfully parsed, for example:
<field tag="WL" occ="1" culture="nl-NL">13e april 2001</field>
In the SQL database the new table type will look something like the following:
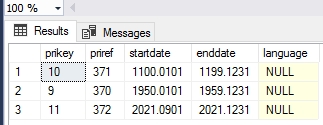
(The language column is currently not in use. Its presence is for possible future use.)
Note that implementing this new field type will break compatibility with older versions of Designer and Collections, but removing the new field, index and screen field should restore that compatibility although the obsolete index table will remain present in the SQL database. Remember to also update your other Axiell software to their latest version, after implementing this new functionality.
2022-10-05: writing the response of an OPENURL call to a file
With the existing OPENURL function you can open a web page in a browser. With the second parameter in the call (the mode parameter) you specify whether you just want to check whether the provided URL is valid (mode = 0) or if you'd like to actually open the URL in a browser window (mode = 1).
In Collections 1.15 a new mode value 2 has been added to OPENURL to be able to save the response of the call to a file, from a storage adapl, without opening the target in a browser window. The file to which the response is saved can be set using the PDEST … FILE instruction. A code snippet with an Axiell WebAPI call in the OPENURL statement to illustrate how this works, is the following:
text url[0]
text path[0]
numeric result
/* Set storage location for API output
path = '..\result_'+ date$(4) + '.xml'
pdest path file
/* Format the URL
url = 'https://ourserver.com/AxiellAPI/wwwopac.ashx?database=collect&search=all'
/* Open url and store output
result = openurl(url,2)
/* Check if HttpStatusCode OK was returned
if (result <> 200)
{
errorm 'Error retrieving or writing response = ' + result + ': ' + error$(result)
}
The path used in PDEST for storing the response is relative to the application folder (e.g. \xplus). Note that for security reasons you can’t write files beyond the application root folder. If you try to do that anyway, OPENURL will result in an error 8 (internal error) with some details.
2022-10-04: improving searchability on values with punctuation or diacritical characters in full text databases(CV1-4397)
In the 1.14 version of Full Text indexed databases, values with specific punctuation and diacritical characters, like in the name "O'Toole, Peter" for example, could only be found when searching on this name including the single quote and comma, so in these cases you always had to know exactly how a name or term is spelled, which was even harder when other special characters are used, like diacritics, brackets or hyphens etc.
That's why from Collections 1.15 you can search on such field values both with or without such special characters (also case-insensitive) and/or use the so-called normalized form of letters with diacritical characters and still find what you're looking for, but you'll have to update your Full Text indexed database to make this possible. This update is mandatory if you already had a Full Text indexed database: if you didn't have a Full Text indexed database yet and you are implementing it for the first time, you already get the updated version immediately.
Via the latest release version of the Axiell IndexTool (which is freely available through our helpdesk) you simply perform this update on your existing database with data. Do make a backup before you execute indextool.exe, just to be on the safe side. Full documentation on this tool can be found here.
Log everyone out of Collections and from a command-line simply execute the tool with the -x argument and the appropriate path to the \data folder of your Axiell system, something like:
indextool -p <path to data folder> -x
This will rebuild the Full Text indexes and add a "stripped" column to the tables, containing the stripped version of field values stored in the record with punctuation or special characters (values without such characters won't get a stripped value). Now whenever the user performs a search, Collections will search both the value and the stripped columns. The only exception are uniquely indexed fields: for such fields the stripped version of a term is not used to find records. So if a uniquely indexed object number contains a hyphen for example, like ABC-1234, you cannot find the relevant record by searching on ABC1234, but you can find it by searching on e.g. ABC* or ABC-1234.
The stripped column can index more than the 100 characters that the term column can, so long titles are indexed here completely. This means you can search on the full title (using the Equals operator) or on one or more words (even beyond the 100 character limit) using the Contains phrase operator (Contains any doesn't search the stripped column currently).
Other Axiell software (besides Collections and Designer) that's been updated to deal with the stripped column, are: IndexTool, WebAPI and the Move server.
See the Collections 1.15 release notes for more information about the new search capabilities for users.
2022-10-03: names of previously hard-coded databases now configurable
For quite some time there have been three areas which entail mandatory database and field names for different Axiell software to be able to deal with those databases:
| • | The reports.inf is an optional database for uploaded output format Word templates per user per data source. |
| • | The missions.inf and request.inf databases are used by the Missions dashboard in Collections. |
| • | The audit.inf is an optional database to log user activities. |
For each, some fields have been hard-coded as well.
In rare cases, when installing or customizing an application when the database is still empty, there may be the wish to rename one or more of these .inf files. From Collections 1.15 you may use different names for these so-called schemas by specifying those in a special schemas.json file which should be stored in the application root folder (so not in c:\model\xplus for example, but in c:\model). A different name for an .inf or field should of course match an actually existing .inf or field definition. You should only change the values of the properties in the file, not add new properties or rename them. You can download schema.json with the default settings here.
You don't need to use the file if you're happy with the current names of the above mentioned .inf's and its fields, and if the relevant tables already contain data you shouldn't do any renaming at all because changing the name of an .inf in Designer also requires you to rebuild the tables in the SQL database, as they should have the new name too, which is best only done if the relevant tables do not contain any data yet.
2022-09-20: quickly accessing the stored version of the currently edited record in ADAPL
Sometimes in an adapl you need to be able to compare the new contents of a currently edited field in an existing record in Collections to the contents of the field before it was being edited (the previously stored content), maybe just to acknowledge the fact that the field contents have changed and have the adapl take some other action automatically and/or maybe because the difference between the new and old value is relevant somehow and needs further action. Maybe someone changes the insurance value of a painting and maybe the difference between the old and new value is so great that flags need to be raised, for example.
Normally you would program this in an after-field adapl or before-storage adapl, by FACS reading the current record - giving you the previously stored version of the record - after which the adapl may compare the current value to the "original" value. Or you would use the ISMODIFIED function to just check if field contents have changed, without getting the original value.
From Collections 1.15, there's new ADAPL functionality which removes the need for a FACS READ action in such cases altogether, boosting performance of such old-new field contents comparisons. The previously stored version of the record is now always available in an implicit, reserved FACS buffer called _original. You never have to declare or open this FACS buffer. To obtain the original contents of a record field from this buffer, you simply use the tag indirection syntaxis behind the FACS name: an exclamation mark followed by the field tag. In an after-field adapl for example, to obtain the previously stored object number (tag IN) from the currently edited record after leaving this field and present a warning message on screen if the object number has changed, could be done with:
if (&1 = 21) {
if (&4[2] = 'IN') {
if (_original!IN <> IN) {
errorm 'You have changed the object number from ' + _original!IN + ' to ' + IN
}
}
}
Notes:
| • | The retrieved original contents must be seen as a (text) string, just like the contents from a field tag or other FACS variable. (If the string constitutes a number, use VAL to convert that number to an actual numerical value with which you can do calculations or numerical comparisons.) |
| • | Only for existing records is the _original FACS buffer filled, not for new records. |
| • | The execution moment of an _original contents retrieval is irrelevant, but after-field, after-screen or before-storage would make most sense of course. |
| • | The _original FACS buffer is read-only so you can't write anything to it nor delete it. Any attempt in an adapl to do so will result in an on-screen error message. |
2022-08-24: journaling data changes in a metadata database
Journaling was possible for regular databases already, but data changes in metadata tables were not journaled yet. From Designer 7.9 and Collections 1.15, this is now possible. On the Metadata database properties tab of a metadata .inf an Enable journal checkbox has been added. Check it and recycle your Collections IIS app pool and next time you add or change record data in metadata fields, those changes will be registered in the automatically created new journal table in the SQL database: dbo.metadata_journal for example if you have a metadata.inf. For now, Collections does not have a user interface to view this journal yet so you'll have to query the table in SQL Server Management Studio to find changes you are looking for.
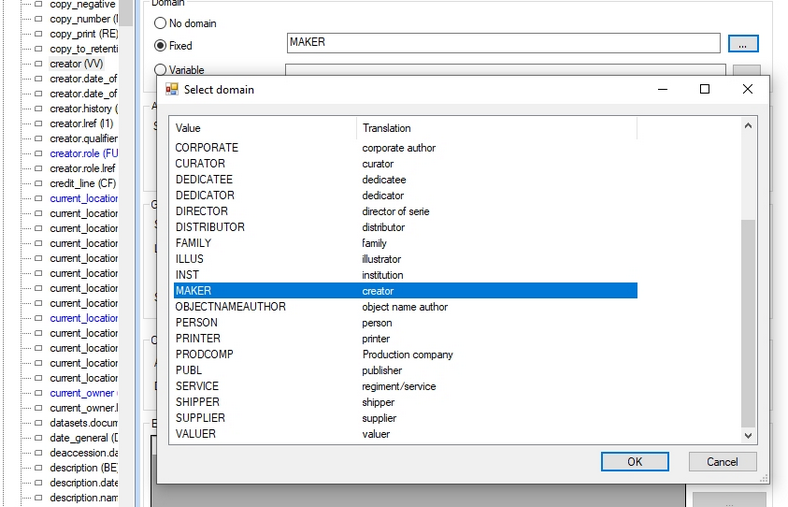
2022-09-05: a validation list for fixed domains
On the Linked field properties tab of a linked field, where you can set a fixed domain, you can now select the (neutral) name of this domain from a list of all available domains for this field, so you don't have to look up the desired value elsewhere and you can't accidentally make any typing errors. Open the list by clicking the ... button right next to the property box. A separate window opens with on the left the neutral value and its user-friendly translation in the currently set application language on the right side. Simply select the desired one and click OK to copy the neutral value to the property box.
You can also still type a neutral value yourself: as long as the value you type does not match one of the neutral values in the list, the background of the property box will be pink. The exception is a Fixed domain which consists of a fixed and variable part, like QUALITY_%record_type% for example: as soon as you type a percent character, Designer knows it can't validate this domain to the list anymore, so it won't show the pink background either.
This addition is available from Designer version 7.9.
2022-09-01: importtool.exe: a new import tool supporting all current database index types
The recently introduced indexed link and full text index types, the triple index type for reverse relation metadata and the metadata database themselves are supported by all Axiell software, but importing new data into databases with these table types could still only be done through Axiell Collections or the internally used Axiell Migration tool. Axiell Designer and import.exe (which normally allow for more complex import jobs than Collections) however, are still not capable of such imports. Therefore, a new import tool, appropriately called importtool.exe, has been developed to support all current database table types used by Collections.
The import jobs themselves can still be made in Designer, but not all options are supported in importtool.exe currently. It does support the following features:
| • | ASCII Delimited (CSV)* and Adlib Tagged import; |
| • | Process links and Process internal links options (on or off); |
| • | Import adapl scripts; |
| • | Clear database prior to running the import job (on or off); |
| • | Setting the default Record owner value; |
| • | The Add new records option (on or off); |
| • | Updating existing records (when Update tag has been filled in), but the Update language option is not used and the Delete data in existing records option is not checked, it is implicitly set to No; |
| • | Changing the default tag separator using the <TS> field mapping option; |
| • | Changing the default record separator using the <RS> field mapping option; |
| • | Milestone value set in import job; |
The Forcing always allowed option is implicitly switched on by default, like in Collections import. The Ignore priref checkbox is assumed to be deselected. Options not mentioned here, are ignored by the import tool.
Remember that after creating the import job in Designer, you should not run it from Designer if your database contains the new types of indexes: then always use the tool.
The command line syntax of this tool is:
Importtool.exe -p <path to import job folder> -i <name of import job> -l <optional path to log file>
* A CSV import with this tool requires a CSV file with a field name row on top (the Collections way, not the Designer way) and it doesn’t use the field mapping in the import job. This means all columns from the CSV file will be imported and you have to use a comma as field separator.