Properties of databases: Advanced

Contents
On the Advanced tab, which is present when you have selected a new or existing database, you may specifiy some advanced properties of this database.
Click here for information on how to edit properties in general. And click here to read about how to manage objects in the tree view in the Application browser. On the current tab you'll find the following settings:
This option is hidden for any .inf with SQL storage set up, from Designer 7.7.6.3209, because Axiell Collections ignores it anyway and always uses a dot as decimal separator to store numerical values. The option will only remain visible for .inf's with the old, now deprecated, CBF storage set up.
Note that the presentation format (dot or comma) of numerical values may be different from the stored format, can be specified per data dictionary field and may be set to depend on the local Windows settings for it. However, the presentation format does not affect the format in print (in both Collections and Adlib). In Collections, the presentation format depends on the selected interface language, while the printed separator depends on the method of printing too: printing to a Word template uses the interface language based separator while printing via an adapl uses the dot as separator.
Exporting from Collections uses the dot.
Further note that the explicit Default setting for this option equals the Dot setting.
Enter the field name or tag of the term status field in the current database, if this database (typically the Thesaurus thesau.inf or Persons and institutions people.inf) has such a field.
A term status field can be used to manage authority records by distinguishing approved and non-approved terms in five different categories. See the general topic: Status management of authority records, for more information.
Use this option to set a Record type field (available from Designer 7.3) if you'd like to have a field that will indicate per record what "type" it is. This type will have to be selected by the user creating the record from a drop-down list.
In Adlib there also existed two other, more common ways of discriminating between record types: you could use datasets, to separate "book" record types from "articles" and "serials" in a library catalogue for example, or domains in an authority database like a thesaurus to be able to specify exactly in which catalogue fields a term is allowed to be used. The Record type field on the other hand, is meant to be used in situations where different catalogue record types must really all be part of one and the same data source, for instance because it concerns a hierarchical data source like an archive in which the different record types must be linked hierarchically.
In combination with other functionality, identifying such a record type field allows you to hide fields on screens using record type access rights or to specify so-called relationship dependency rules controlling how different record types can be linked. In itself, having a record type field does nothing: it has no consequences and merely offers the possibility to implement other functionality which relies on a record type field.
As an example, suppose you have a film archive catalogue which contains four record types which can be linked hierarchically in some way: WORK (e.g. a story or script for example), MANIFESTATION (e.g. a movie or a theatre play), ITEM (e.g. a film reel, dvd) and VARIANT (maybe a black and white version of the movie). Because of the hierarchical links you couldn't have separated these records by means of datasets. Instead you can define a simple enumerative field to set each record to one of these four types. This will of course already allow you to search on record type and/or to show or hide conditional screens and fields dependent on the current record type, but after you specify the enumerative field as the Record type field for the database too it also allows you to implement other functionality like relationship dependency rules to determine if a WORK can only be linked to a MANIFESTATION or to an ITEM as well, and if a VARIANT must always be a child of an ITEM or can it also be a parent of a MANIFESTATION, etc.
Simply look up the desired, existing field in the current database by clicking the button with the ellipsis to the right of the entry box or type the desired tag or field name. If the field name or tag turns red, you've entered an illegal tag or field name. Fields which can be used as the record type field, must be enumerative* and must have been indexed with the (index) Key type option set to Text. A second recommendation is that you make sure that when a user starts editing a new record, a default value is already present in the field or that entering a value into this field manually is really one of the first things the user has to do. The reason is that you'll likely be using the record type field contents to determine which (conditional) screens or fields will be displayed to the user next and/or to which other record types this record is allowed to link.
* If you'd like the enumerative list of the designated record type field to show different values for the different datasets in a database, you can use the Field properties per dataset functionality to redefine the record type field and its enumerative list per deviating dataset and override the default field specification on database level. This allows you, for example, to offer different record types for the archive and object datasets (which are part of the same database).
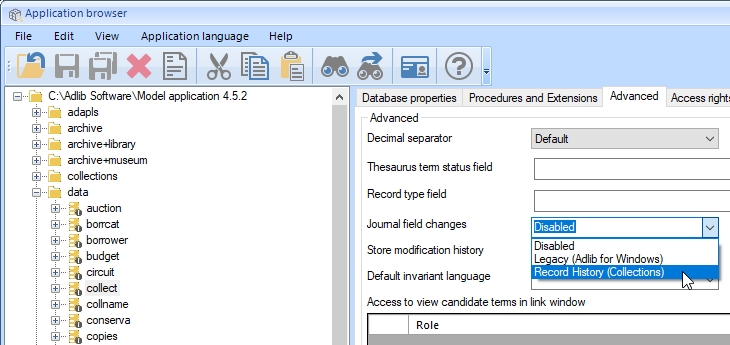
If you are using a SQL Server database, you can use this setting (Legacy as a checkbox available from Adlib 6.6.0 and Record history available from Adlib and Designer 7.6 and Axiell Collections 1.4) to let Collections and/or Adlib log all saved changes in records in the current database. This allows for easy backtracking to see who, when and which changes have been entered, or you can use the change log to find the original data when incorrect data has been filled in. Legacy edit history can be viewed per field in Adlib while Record history (Collections) data can only be viewed in Collections. So the main purpose of this setting is to log field data when it changes, so that if you or someone else has changed existing data in a field and saved it, and only later you realize the new data is wrong and you want the old data back, then you can retrieve that old data if you have set this option. See the online Collections Help for information about how to do that from a user perspective.
The following three options are available to you:
| • | Disabled - no journalling takes place in Adlib for Windows nor Axiell Collections. |
| • | Legacy (Adlib for Windows) - journalling is switched on for Adlib for Windows only (it doesn't break Collections, but you can't access the journal in there either). After setting and saving the Legacy option, in the relevant Adlib database table in the SQL Server database an extra record will be created for every record which has been edited by a user, and this extra record will have the negated number of the original record number: for example, the first change in a record with the number 171 causes the creation of a record with the number -171. In this “negative” record, all* changes in the record will be logged from now on: each data change will be saved in a new field occurrence in this record. Note that the size of your database will increase substantially. * Only changes in linked fields and any merged-in fields won’t be logged. |
| • | Record history (Collections) - with this setting, journalling is switched on for both Axiell Collections and Adlib for Windows (7.6, from 21-3-2019). If you were using the Legacy option already for Adlib for Windows, we recommend only switching it to Record history (Collections) if you have access to the Axiell DBTool.exe tool to convert your Adlib journal to the Collections Record history journal, since Record history uses a different journalling technique than the Legacy option and you may want to hold on to the journal data accumulated by Adlib for Windows. Ideally, converting the old journal format to the new format must be done right after changing the current setting from Legacy to Record history (Collections), but conversion at a later stage is possible too. If you haven't converted any existing Adlib journal after switching to the Record history option, Adlib will generate an error every time you try to edit a record with associated journal data in the old format, to prevent the two types of journals from diverging. Even though with the Record history option editing records in Adlib will be journalled just like editing records in Collections, Adlib for Windows won't get a user interface bit to view the journalled data in the new format: for that you need Axiell Collections. |
Make the change per desired database definition: you may change them all or just a few.
The change to Record history (Collections) will automatically add a special table to the SQL Server database, in which the change log for the relevant database table will be kept, once the table is accessed in Collections (or by the WebAPI). Until late 2019 this table was named dbo.journal.<database name>. Later, such a newly created table by Collections was named <database name>_journal (e.g. collect_journal) to bring it in line with typical table naming practices. The WebAPI wasn't updated at the same time though. Up until the 30 March WebAPI release, the WebAPI only knew about the old name, so when the WebAPI was used to edit data, it created a journal table with the old name when it checked for its existence when writing data. If a journal with the new name already existed, which could only have happened if the Record history style of journalling was switched on late 2019 or in the first half of 2020, then an undesirable two journal tables would now exist for the same database table. From later releases of Collections, the WebAPI and Adlib (7.6.20055.2 or higher) though, both journal table names are recognized (although a new one will always be created with the new name), in order to prevent the doubling up of journal tables. So an update to the latest release of the WebAPI is recommended if you use the WebAPI to amend data and you have journalling switched on.
If your SQL database still has journal tables with the old names, you can leave them that way, but you can also change their names to adhere to the new format, if you want, but then be sure to recycle all services that can write to the SQL database, afterwards!
Apart from the options above, there's an advanced option for SQL Server power users. Per database definition you can switch on SQL Server Change Tracking. This mechanism can be used to query the SQL database for changes in rows of a specified table. These changes can be inserts, updates and deletes.
Simply right-click the desired .inf and select SQL Server Change Tracking > Enable change tracking in the pop-up menu. (SQL Server Change Tracking > Disable change tracking would switch it off again.)
This option is not implemented for Axiell Collections.
For multilingual databases you can set a default invariant* data language. If you set this option, set it to one of the data languages already available in your application (as set on the Advanced tab of your application structure (.pbk)). Once you select a language, you'll have to confirm that the setting will be copied to all other database definitions in this \data folder.
Once set, editing data via the Multilingual data dialog for a mulitlingual field in Axiell Collections will behave as follows when it comes to the invariancy aspect of a translation:
| • | If one of the translations in a multilingual field has already been made invariant manually, nothing will be done with the default invariant language: the data will remain as is. |
| • | If no value has been entered in the data language that you've set as the invariant data language, nothing will be done with the default invariant language, regardless of whether any of the other translations have been set to be the invariant or not: the data will remain as is. |
| • | Currently , if none of the translations in a new or edited record have been made invariant already, while the user is currently adding a translation in the default invariant language, then on saving the record, invariancy will be applied to that translation. During editing of said translation the invariancy radio button behind the edited value will remain empty though, even though the user doesn't have to mark it manually, so there's no visual clue that this value becomes the invariant value upon saving of the record. |
| • | Currently , if none of the translations in a new or edited record have been made invariant already, while a translation in the default invariant language is already present, then on opening of the Multilingual data dialog (either in display or edit mode), then the invariancy radio button for the default invariant language will appear marked anyway, but this invariancy will only be really applied when the record is edited and saved. There is no visual clue that the marked radio button doesn't represent the saved state of that translation. |
* Invariancy is meant to make translating easier: an invariant value is not only displayed in the field if the data language is set to the language of that value, but also in other data languages for which no translation exists yet (in which case in display mode the data is presented in a light grey font while in edit mode the field has a light blue background to indicate that an invariant value is being displayed). An invariant value in a light blue field is hidden as soon as you type something into the field.
Access to view candidate terms in link window
The Show candidate terms checkbox in the Find data for the field window for linked fields in catalogue records can be hidden from certain user groups via access rights, if you don’t want everyone to be able to view and/or link candidate terms (these are terms which haven't been approved yet). Set those access rights here in the Access to view candidate terms in link window list on the Advanced tab of the relevant authority database (the Thesaurus or Persons and institutions). For all fields linked to this authority database from within some other database, the checkbox will then be hidden from users with a role which has been assigned the access rights No. By default (without having set any access rights), users do have access to candidate terms.