Notes de version 1.15

Contents
The Microsoft .NET Framework Runtime version 4.8 must be installed on the IIS server running Collections (after which the server needs to be rebooted). Ask your system administrator if this still needs to be done.
New options and functions for Axiell Collections make further use of Adlib for Windows impossible
Some of the new functionality introduced in this version and previous versions of Collections requires to be set up by your application manager (as indicated per topic in the various Collections release notes), using new options in Axiell Designer. Since development of Adlib for Windows has ceased quite a long time ago, these new options are not supported by Adlib for Windows. Even if Adlib would ignore the relevant option, you could no longer reliably work in Adlib too, so altered applications using Collections-only functionality should never be opened in Adlib again.
New Collections online Help
The current English version of the Collections online Help you see before you, has been revamped and moved to a different URL: http://help.collections.axiell.com/. To have your Collections application open that new version automatically, your application manager will have to make a simple change to the Collections settings.xml file: almost at the top of that file, the <Help>http://documentation.axiell.com/alm/collections/</Help> reference (which points to the current version) should then be replaced by <Help>http://help.collections.axiell.com/</Help>. After recycling the application pool, clicking the Help button in the main toolbar on the left, will open the new Help version if you're connected to the internet.
Note that the new version will only be present in English for now. If you make the change above and you click the Help button, you will always be redirected to that English version, regardless of the interface language currently active in Collections. Since the current Collections online Help is available in Danish and French too, users in those language regions are probably better off leaving the <Help> setting as it is, as this will still allow you to use the Help in your own language.
2022-11-30: release Axiell Collections 1.15.1
Today we release Axiell Collections 1.15.1, offering the bug fixes and new functionality described below.
Bug report no. |
Short problem description |
CV1-4704 |
Clicking on a linked field in a zoom screen did not open another zoom screen but made the application non-responsive. |
CV-4677 |
Very large advanced search strings for Text or Free text indexes caused a crash of the Collections application pool. |
CV1-4667 |
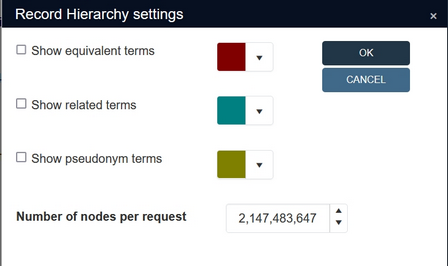
It was not possible to set the Number of nodes per request option in the Record hierarchy settings for the Hierarchy browser, to more than 1000. Any higher number would be reset to 1000. Beware that changing the limite to a higher value will have a negative impact on performance! |
CV1-4586 |
The application id (set in the application configuration) could no longer be used to set access rights, causing screens and data sources not part of the licensed application to become visible in Collections (where they are normally hidden with appropriate access rights). |
2022-10-31: release Axiell Collections 1.15
Today we release Axiell Collections 1.15, offering the bug fixes and new functionality described below.
Bug report no. |
Short problem description |
CV1-4603 |
There was incorrect duplicate key error when saving a particular object record. |
CV1-4590 |
Searching on enumerative fields using interface language specific values no longer worked in full text enabled applications. |
CV1-4573 |
Rows in a record table grid would display briefly and then disappear if there were field suppress conditions on non-repeatable fields. |
CV1-4567 |
A Contains any standard search using wildcards returned no hits. |
CV1-4562 |
When searching on an empty string in an inherited field, records with an inherited value would still end up in the search result although that value was not stored in the record (so the field was actually empty). |
CV1-4557 |
In a Full Text indexed database, searching on part of a reference with special characters [ ] - found too many records. |
CV1-4554 |
There was a primary key constraint error when running a search for an empty string. |
CV1-4549 |
If you edited a linked record in its zoom screen, then upon saving it, the Record details view suddenly showed the linked record while if that record didn't exist in the current data source, an empty Record details view was shown. |
CV1-4544 |
Clicking a record in the Result set view did not always populate the Record details view. |
CV1-4540 |
An after-field adapl, sorting and the Assigned to me filter function for a certain workflow implementation didn't work. |
CV1-4521 |
Setting a field value in a multilingual field to Invariant, did not have any effect. |
CV1-4520 |
There was a double ... icon at the bottom of a partial list in the Related records view. |
CV1-4507 |
Data in a multilingual link field was deleted, if you changed the data language and edited the record. |
CV1-4497 |
When sorting a Resut set on an inherited field, records with inherited values (which are not stored in the record) always ended up at the top or a the bottom of the list because to the sorting algorithm these fields were empty. |
CV1-4491 |
Certain sorting conditions set up for an access point, resulted in an "Unexpected token, expected " instead of ‘occurrences'." error when Standard searching this access point. |
CV1-4488 |
In certain situations, an incorrect value from a linked field occurrence could be merged in. |
CV1-4484 |
The options for dealing with field occurrences had gone missing from the CVS Settings dialog for exports. |
CV1-4477 |
It was no longer possible to add a recipient e-mail address to a saved search schedule. |
CV1-4469 |
In a customised application (with record access rights and Default access rights set to None while the Record access user, Record access rights and Record owner fields were set by the storage adapl), it was not possible to add a new Document record: "No read access for record". |
CV1-4468 |
When doubleclicking a field in windows containing two fields lists, the field moved to the other list was displayed in the middle of the box instead of at the top of the box or just below the other fields. |
CV1-4461 |
Sorting on the uniquely indexed reference_number (IN) field in the Result set did not work in a Full text indexed database. |
CV1-4459 |
Which value in a repeatable field was used for sorting the record in the Result set, depended on sorting Ascending or Descending. |
CV1-4457 |
Adding a new occurrence in a detail or zoom screen cleared the content of the already existing occurrence. |
CV1-4444 |
The Record details settings Filter mode Has Data would also hides tabs and fields in edit mode (as documented), instead of just in display mode which makes more sense. |
CV1-4441 |
Moving records from one dataset to another using a task did no longer work because due to a code change in 1.14.1, access rights were not checked fully correctly anymore, prohibiting the move. |
CV1-4432 |
Sorting on the Result set column for a merged-in field no longer worked. |
CV1-4411 |
When a new Archive (catalogue) record was created by the ADAPL command write _LOCAL, then the PID fields were not filled. |
CV1-4393 |
When navigating records via the Related records view, names of active data sources (as displayed large above the Result set) were wrong. This was due to a previous code change in 1.14.1, causing access rights to not be checked entirely correctly anymore, disallowing access to some data sources. |
CV1-4293 |
The task summary window's OK button was not always visible or displayed. |
CV1-4291 |
If the request.inf database name was changed to something else, clicking the mission items link button in the Axiell Move dashboard resulted in an error, because request.inf was the mandatory name. Solved with new functionality to configure previously hard-coded database names: please see the Designer release notes. |
CV1-4273 |
When exporting Attached media, the field list on the right showed remembered fields from the last (non-media) export, but those are not relevant here. |
CV1-4237 |
It was possible to create links to a linked record when another user had locked that linked record for editing. |
CV1-4190 |
After saving a new record, the displayed record became the before-last one in the result set (which was not the record you just created). |
CV1-4150 |
JQuery libraries were outdated, causing a possible security risk. |
CV1-4104 |
Editing Use/Used-for fields when for the Thesaurus the Thesaurus itself was set up as feedback database, generated an error. |
2022-10-20: (natural language) period-to-dates conversion
Collections 1.15 allows your application manager to implement a new Period field type in your application. With it, you can enter and save date periods expressed in natural language, like "12th century", "Spring 2022", "late 2018", "Early 19th Century - 2022", "1950s" etc., in a record while the indexed values actually become date ranges in the form of real (numerical forms of) ISO start and end dates, like 1100.0101 - 1199.1231, 2022.0301 - 2022.0531, 2018.0901 - 2018.1231, 1800.0101 - 2022.1231 and 1950.0101 - 1959.1231 respectively: you will never see these ISO dates as the entered natural language date period will be saved in the record However, when you search this field, you can only search it on complete natural language periods, like "12th century" (and years in digits), not on single words (not even truncated) from the natural language period like "century" nor on ISO dates which include months and/or days. So the search language “parser” (the code that processes your data entry) converts the search key to an ISO date range too. If you search on a broad period, the search will not only yield that exact period but also narrower periods within that broader period. One can currently only search on a single date period, not on date period ranges. A full overview of all English natural language period elements that can be entered in a Period field (or when searching this field) can be found here. Supported languages in Collections are currently British English, Dutch, Danish, Welsh, Portuguese and Swedish. Parsing of date entry in this field depends on the current user-interface language in Collections, so while working in the Dutch UI language you'll have to enter date periods Dutch and while in English you should enter date periods in English. The same applies to searching, so in Dutch a user would search for e.g. my_period_field from "21e eeuw", while in English you search for my_period_field from "21th century", but in both scenarios you would find the same records because the index is language independent.
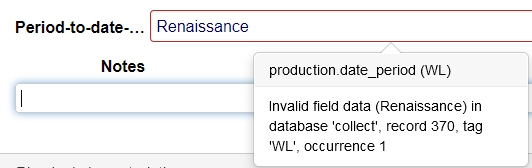
Validation takes place after changing and leaving the field. If you enter a period that isn't recognized by the parser, a warning will be shown similar to the one below (although field name and field tag can be different) and you will have to enter a different period.
2022-10-10: marking the currently displayed record for your selection
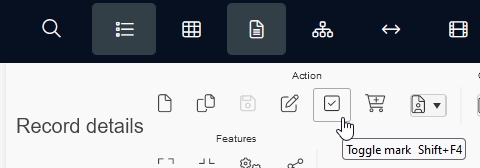
When you create a record selection (for printing, search-and-replace, deletion, etc.), you could already do that from the Result set context toolbar, but from Collections 1.15 you can also mark (or deselect) the record currently shown in the Record details view by just clicking the new Toggle mark icon (or pressing Shift+F4), so you don't have to have the Result set view open anymore to create a record selection. The state of the icon in the Record details context toolbar shows if the currently displayed record is already selected or not: if the icon seems pressed down, the record is selected, otherwise it's not.
2022-10-10: number of marked records now visible in Record details and Result set status bars
From Collections 1.15, the status bar of both the Result set as well as the Record details view will now always show how many records you have currently marked (zero if none were marked). If doesn't matter if you mark records in the Result set or in the Record details view.

2022-10-03: improved searchability on values with punctuation or diacritical characters in full text databases
From Collections 1.14 it is possible that your application manager has implemented so-called Full Text indexes in your database. For you as an end user, this means an increase in search performance in long text fields, fields with non-unique terms and linked fields plus the new ability to use real phrase searching in such fields and to use the Starts with operator in the Standard search.
However, even in such Full Text indexed databases, values with specific punctuation and diacritical characters, like in the name "O'Toole, Peter" for example, can only be found when searching on this name including the single quote and comma, so in these cases you'll always have to know exactly how a name or term is spelled. This may be even harder when other special characters are used, like diacritics, brackets or hyphens etc.
That's why for Collections 1.15 there's now the option to search on such field values both with or without such special characters (also case-insensitive) and/or to use the so-called normalized form of letters with diacritical characters and still find what you're looking for, but only if your application administrator has has made this possible through an update procedure for the database (please see the Designer 7.9 release notes for more information about that).
Spaces are still spaces so you still have to enter those in search keys consisting of multiple words, but in the new situation a name like O'Toole, Peter can now be found using search keys like O'Toole, Peter, OToole Peter, O'Toole Peter, otool peter or otool*.
To be precise, the following characters or combinations of characters can be omitted (but you can leave them in as well) when searching a Full Text indexed database with the new normalization functionality:
"[", "]", ";", ",", "!", "@", "(", ")", "|", "{", "}", "<", ">", "?", "\r", "\n", "\t", "`", "-", "=", "\\", ".", "/", "~", "#", "$", "%", "^", "&", "_", "+", ":", "\"", "\'", "*"
Letters with diacritical characters like accents and such can be searched on using their normalized version (case-insensitive again). So instead of entering an "á" or "Á" you can just enter an "a", while an "æ" can be entered like "ae" and an "Ø" or "œ" by "oe" for example.
The only exception to stripped searching are uniquely indexed fields: for such fields the stripped version of a term is not used to find records. So if a uniquely indexed object number contains a hyphen for example, like ABC-1234, you cannot find the relevant record by searching on ABC1234, but you can find it by searching on e.g. ABC* or ABC-1234.
The stripped searching functionality also allows searching on values longer than 100 characters (which used to be a limit in certain cases). This means you can search on the full value, a long title for example (using the Equals operator in the Standard search) or on one or more words (even beyond the 100 character limit) using the Contains phrase, Contains any or Contains all operator.
2022-10-03: output format types now indicated by different icons
Output (print) formats in Collections can generate different types of output. An icon in front of every output format in the Output formats window now indicates which type you can expect when using the relevant format.

The icons have the following meaning:
![]() A Word document will be created and saved to your Downloads folder.
A Word document will be created and saved to your Downloads folder.
![]() An XML or HTML page generated by an XSLT stylesheet and saved to your Downloads folder.
An XML or HTML page generated by an XSLT stylesheet and saved to your Downloads folder.
![]() A CSV, text or PDF document will be created by an adapl and opened in your browser.
A CSV, text or PDF document will be created by an adapl and opened in your browser.
![]() Any other output format type not included in the above categories.
Any other output format type not included in the above categories.
2022-09-29: active data language displayed in title bar
in a multilingual application, it's good to have a constant reminder of the currently active data language so you're not accidentally entering data in the wrong language. To that end, that data language is now displayed in the title bar of the application, next to the data source name.
2022-09-29: saved search settings remembered per user
Your personal column sorting and filtering settings on the Saved searches tab in the Search <data source> dialog and in the Manage saved searches window are now remembered by Collections, so you won't have to set these options again each time you open the tab or window.
You can tell whether sorting is applied to a column by a blue arrow in the column header, whilst an active filter is indicated by the black funnel icon in the column header. Click either icon or the three-dots icon to change any sorting or filtering.

2022-09-20: choosing which data sources are visible in the Select data source window
By default, the Select data source window, which opens after you click the Search or New button in the menu on the left, shows all data sources which are available to you to work with. This can be quite a list, while you may not actually use all of these data sources. Therefore, in Collections 1.15 you can now make your own selection of visible data sources in this window, to hide all the ones you're not using anyway. Simply click the Settings button in the Select data source window.
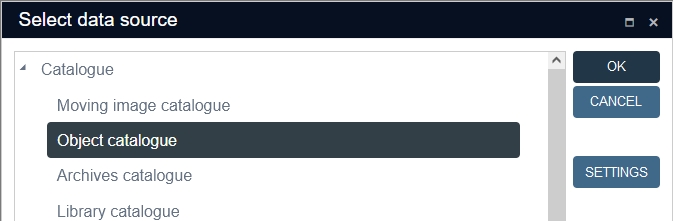
In the Data source settings window, the list on the right shows your current selection of visible data sources. The list on the left shows the currently invisible data sources. Simply double-click a data source to move it to the other list, or use the Remove button to move a selected data source from the right list to the left one or use the Add button to move a selected data source from the left list to the right one.
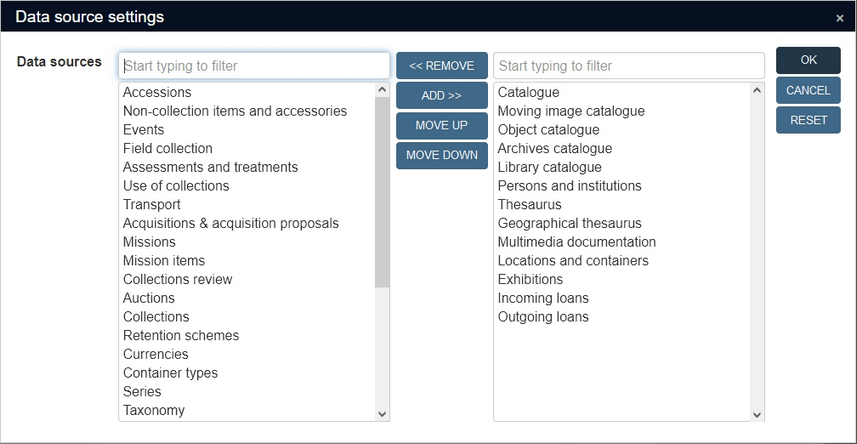
The above settings would lead to:
You can even change the order in which the data sources in your selection appear in the Select data source window. Simply select a data source in the right list and click the Move up or Move down button to change the order. Note that you can move sub data sources outside of their parent data source: that is not a problem, but you may loose overview of which sub data sources belong to which parent data source this way: after all, when you search the parent data source, the Catalogue for example, it's good to have a visual reminder that (in this particular application) you're actually searching the Moving image catalogue, the Object catalogue, the Archives catalogue, the Library catalogue, Accessions and Non-collection items and accessories together (even if some of those data sources are hidden from view here).
You can also resize the Select data source window by dragging one of its borders up, down, right or left.
Your settings will be remembered in your user profile, so next time you open the window it should present itself the same way.
To get the data sources list back the way it was originally, simply click the Reset button in the Data source settings window.
2022-09-09: importing CSV files with a special character encoding
The CSV settings dialog, which is available after clicking the Settings button in the Import dialog after selecting CSV as the source file format to import, now offers a new Encoding drop-down.
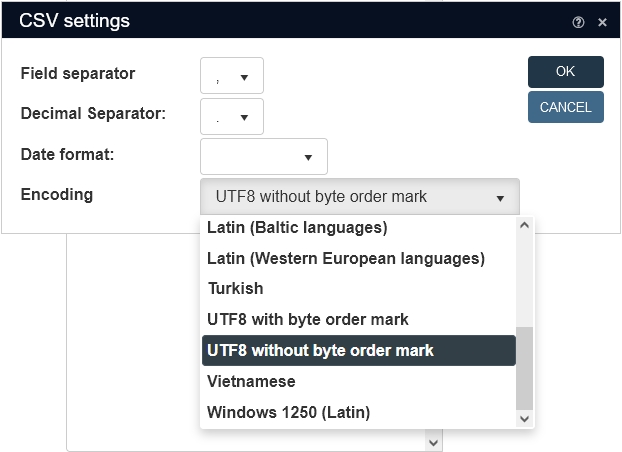
Here, you must specify the encoding of your import file for anything other than UTF8 with byte order mark (although you can select it here explicitly too). When the import file has a BOM (byte order mark, a hidden character in a file, indicating to the processing software which Unicode character encoding to expect from the file), the file’s encoding will be used, otherwise the selected encoding will be enforced. The default setting is UTF8 without byte order mark. You can find out which encoding your import file has by opening it in Notepad++ and opening the Encoding menu: the current encoding will be marked with a black dot in front of it. UTF-8 equals UTF8 without byte order mark.
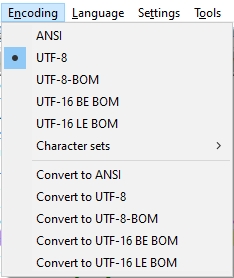
The consequence of having the wrong Encoding selected might be that some characters are converted to other characters during import, which of course is not desirable.
CSV files created in MS Excel are usually encoded as UTF-8 (without byte order mark), so this matches the default setting in the Import settings dialog.
In Collections versions prior to 1.15, ASCII was the implicitly assumed encoding for all imported CSV files without BOM, while UTF8 with BOM was assumed when a BOM was present.