Notes de version 1.14

Contents
The Microsoft .NET Framework Runtime version 4.8 must be installed on the IIS server running Collections (after which the server needs to be rebooted). Ask your system administrator if this still needs to be done.
New options and functions for Axiell Collections make further use of Adlib for Windows impossible
Some of the new functionality introduced in this version and previous versions of Collections requires to be set up by your application manager (as indicated per topic in the various Collections release notes), using new options in Axiell Designer. Since development of Adlib for Windows has ceased quite a long time ago, these new options are not supported by Adlib for Windows. Even if Adlib would ignore the relevant option, you could no longer reliably work in Adlib too, so altered applications using Collections-only functionality should never be opened in Adlib again.
New Collections online Help
The current English version of the Collections online Help you see before you, has been revamped and moved to a different URL: http://help.collections.axiell.com/. To have your Collections application open that new version automatically, your application manager will have to make a simple change to the Collections settings.xml file: almost at the top of that file, the <Help>http://documentation.axiell.com/alm/collections/</Help> reference (which points to the current version) should then be replaced by <Help>http://help.collections.axiell.com/</Help>. After recycling the application pool, clicking the Help button in the main toolbar on the left, will open the new Help version if you're connected to the internet.
Note that the new version will only be present in English for now. If you make the change above and you click the Help button, you will always be redirected to that English version, regardless of the interface language currently active in Collections. Since the current Collections online Help is available in Danish and French too, users in those language regions are probably better off leaving the <Help> setting as it is, as this will still allow you to use the Help in your own language.
2022-09-08: release Axiell Collections 1.14.1
Today we release Axiell Collections 1.14.1, offering the bug fixes described below.
Bug report no. |
Short problem description |
CV1-4414 |
Exporting to Excel returned an error if media to be exported couldn't be loaded. |
CV1-4412 |
Error message at login in some multi-tenancy applications: The method or operation is not implemented. |
CV1-4411 |
When a new archive (catalogue) record was created by the ADAPL command write _LOCAL then the PID fields were not filled. |
CV1-4408 |
The sorting order of a table grid for an "indexed link" list of linked records was not correct. |
CV1-4404 |
The Result set turned up empty after a first bulk creation operation. |
CV1-4403 |
The Record details view did not refresh after the creation of a new record via bulk creation. |
CV1-4401 |
Any storage adapl generated error message was not displayed after a bulk create operation. |
CV1-4400 |
A "Violation of primary key" error could appear when opening the Saved searches tab. |
CV1-4392 |
Using the Create entry button in the Find data for the field window for a multilingual linked field, produced an error when saving the record. |
CV1-4389 |
Sorting on a linked field column in the Result set failed if the linked field was multilingual. |
CV1-4377 |
The German data source selection window title: Wählen Sie eine Datenbank was not correct and was changed to Wählen Sie eine Datenquelle. |
CV1-4373 |
When deleting a record (with full text indexing in place), the index tables for unique indexes were not updated. |
CV1-4370 |
Deep links were not working in a multi-tenancy setup. |
CV1-4367 |
The Collections application startup time was a bit slow. |
CV1-4361 |
In a multilingual application, the autocomplete list for linked fields did not show the general prohibition sign in front of non-preferred terms. |
CV1-4360 |
Multi-lingual linked fields in a table grid could not be emptied. |
CV1-4358 |
Dutch labels for the Create entry (Accepteer link) and Create and edit entry (Creëer en bewerk link) buttons in the Find data for the field window were found to be confusing, so they have been changed to Creëer en Creëer en bewerk respectively. Moreover, if you hover the mouse cursor over one of the buttons, a tooltip with an extra explanation of the function of that button will show. |
CV1-4352 |
When sorting of occurrences had been set for certain fields, saving records with a lot of those occurrences could take very long if there was an indexed link setup for the internal hierarchical relation. |
CV1-4345 |
When trying to remove a child record from a parent hierarchy, you were correctly able to remove the parts record, but after saving the record it re-appeared if there was an indexed link setup for the internal hierarchical relation. |
CV1-4341 |
An inherited field (linkref) in one database was incorrectly written in its reverse link in the other database when you edited and saved a child record that had an inherited value. |
CV1-4331 |
The sorting/order of the autocomplete list and the list in the Find data for the field window was not alphabetical anymore, when using the external AAT thesaurus. |
CV1-4330 |
The Related records view could disappear while navigating related records. |
CV1-4327 |
Deleting object records in a full text database was not possible because of an Invalid object name collect_title error. |
CV1-4326 |
Searching in e.g. the Archive catalogue via the Standard search form on any field in a full text index application produced an Invalid object name 'collect_titlterm' error. |
CV1-4325 |
Linking an object on Linked objects screen using the Saved searches tab in the Find data for the field window, was not possible for the first occurrence of the linked field. |
CV1-4324 |
Importing numeric values containing a decimal comma didn't give an error message for invalid content, but instead accepted and removed the comma. |
CV1-4318 |
The Find data for the field window showed an error when a user didn't have access to a data source but did have access to the database. |
CV1-4312 |
In the Result set, if the current record was deleted then all existing record marks/selections were removed from the Result set and the highlight position was reset to the first record. |
CV1-4310 |
Normal (non-full text indexed) databases offered the Starts with standard search operator for Text indexed access points, which was not correct. |
CV1-4308 |
When the UI language required a comma in numerical fields in table grids, a dot was still accepted on entry but not saved, so the data was corrupted. |
CV1-4307 |
Import sometimes gave an Object reference not set to an instance of an object error. |
CV1-4305 |
There was an after-field adapl date assignment issue, resulting in an Invalid field data error. |
CV1-4301 |
Some custom screens were missing from the Record details view. |
CV1-4300 |
There was a task adapl date assignment issue, resulting in an Invalid field data error. |
CV1-4297 |
In the Thesaurus is was possible to remove a term.type value from a term even when that term was in use. |
CV1-4292 |
If you selected a filter value for a linked field from the drop-down list, Collections failed to do anything when the Filter button was clicked. |
CV1-4272 |
The Disable download property and Disable download condition property for image fields were ignored for the media export functionality. |
CV1-4262 |
An invalid value in a numeric field did not display and did not generate an error message either. |
CV1-4255 |
The Record details view settings were reset to their defaults after a new search, and not remembered. |
CV1-4250 |
An indexed link configuration didn't show all links in a linked field. |
CV1-4232 |
Removing a value from a mandatory field in an existing records allowed saving the record and automatically put back the removed value. |
CV1-3866 |
Using a minus character as the boolean operator AND NOT returned incorrect search results in word indexed fields. |
CV1-3819 |
For large images, one could only get part of the image to display in the Media Viewer, even after zooming out. |
CV1-3787 |
Removing a linked field did not remove all metadata records from the database. This made it impossible to add new data to the occurrence. |
CV1-3780 |
Some geographical maps did not display. So the Tile matrix set property in the relevant maps record for this service should be set to KortforsyningTilingDK. Axiell Collections 1.14.1.8250 or higher is required to be able to display this type of map. |
CV1-3760 |
A Boolean combined Standard search on an enumerative filed gave a Field '' not found at combining error. |
CV1-3187 |
Default field values couldn't be applied to write-back fields. |
CV1-2983 |
For numerical fields with zero's padding, clicking in the field in edit mode didn't remove the thousand-separator character from the entered value. |
CV1-2750 |
A selected record was no longer highlighted in the Result set after editing and saving that record in the Record details. |
2022-07-14: release Axiell Collections 1.14
Today we release Axiell Collections 1.14, offering the bug fixes and new functionality described below.
Bug report no. |
Short problem description |
CV1-4320 |
An 'Object reference not set to an instance of an object' error appeared when searching a data source in which a linked field was present for which fields in the Linked field mapping did not have field definitions. |
CV1-4318 |
The Find data for the field window showed an error when a user didn't have access to a data source while he or she did have access to the database. |
CV1-4309 |
Users were prevented from seeing data in fields where it should appear because Collections applied the permissions from the adlib.pbk instead of the relevant database's .inf file. The result was that fields that are merged in from data sources that do not appear on a user's Select data source screen did not appear in records where they should. |
CV1-4296 |
The order of the columns (after changing them) in the Managed saved searches window was not persistent. |
CV1-4276 |
After entering a non-existing term in a linked field, the Find data for the field window didn't contain the term in the search key field anymore. |
CV1-4271 |
Some single-sided connect entities didn't work anymore, |
CV1-4270 |
The ADAPL formatfield function returned an empty string if called from a before storage adapl. |
CV1-4247 |
$ADMIN users could not edit record access rights. |
CV1-4241 |
An advanced search on a link reference tag of an indexed link field returned an error: Invalid column name 'term'. Invalid column name 'priref'. |
CV1-4238 |
An error 8 (Internal error) occurred when writing a record, using FACS, with an "indexed link" reverse link filled. |
CV1-4236 |
Setting a linked field text value via an adapl no longer assigned the link reference value. |
CV1-4230 |
The sort fields list for an Indexed link configuration didn’t offer a (Free text and Text indexed) title field. |
CV1-4228 |
A search-and-replace with the Remove occurrence option marked terminated the replacement job when a record with only one occurrence was processed. |
CV1-4224 |
A logical field merged in with a linked field mapping, displayed as a text field instead of a checkbox. |
CV1-4223 |
The Write once setting blocked saving of an existing record in which the WriteOnce field had not been changed. |
CV1-4220 |
Sorting on two fields in an advanced search statement was problematic. |
CV1-4211 |
After refreshing the Result set, the collect record that had just been linked to a loan record via a customized task was not retrieved anymore. |
CV1-4206 |
Error when date field's default value was set to Current date while the interface language was Arabic. |
CV1-4204 |
After switching to interface language Arabic (right-to-left) records could not be saved due to a date/time conversion issue. |
CV1-4201 |
After clicking on a parent (broader term) or on a child (narrower term) in the Thesaurus, clicking again on the original term did not work. Even when clicking on it in the Hierarchy browser, it didn't work. |
CV1-4198 |
Error messages from a task adapl were displayed twice. |
CV1-4197 |
The Add, Remove and Edit buttons were cut off on the right side in the Manage saved searches dialog. |
CV1-4196 |
A Bad request was reported when clicking the Create entry button in the Find data for the field 'mission_item.action' dialog. |
CV1-4193 |
The ADAPL openfile command in a task screen adapl returned the error 'Value cannot be null. Parameter name: path1'. |
CV1-4187 |
Searching a non-indexed field resulted in a set with as many hits as there were occurrences with the search key in total. |
CV1-4186 |
With the interface language set to Spanish, columns in the Result set were displayed as "data/people/do", "data/people/n4" instead of their field names. |
CV1-4183 |
When searching for a GeoLocation the font used was white on a white background. |
CV1-4180 |
Reverse relation loans->collect was no longer shown. |
CV1-4166 |
All access restrictions set in the .pbk were ignored. Only .inf restrictions were still honored. |
CV1-4165 |
System variable &4[1] (current screen/tab name) only worked in before edit/input adapls, not in other event adapls (after field, before storage, etc). |
CV1-4163 |
The example <SingleSignOn ClientId="[your client id here]" Authority="https://login.windows.net/[your tenant id here]/" Provider="Azure" /> setting in the settings.example.xml file was not commented out previously, which caused a server error in Collections if no BaseUrl had been set as well, because any active SingleSignOn setting (even without actual ids) requires the BaseUrl to be set too. |
CV1-4157 |
Advanced search operators WHEN and WHEN NOT returned incorrect results. |
CV1-4149 |
User names were stored in cookies. |
CV1-4146 |
Field lists in the Related records settings window did not default to the English (reverse) relation texts when translations were missing. |
CV1-4145 |
A detached Record details view showed up blank. |
CV1-4144 |
The Count function on the Standard search form did not respect an active (search) filter. |
CV1-4143 |
A detached Record details view displayed repeated enumerated field values spread all over the screen. |
CV1-4142 |
Connect entities failed for some datasets, although linking them via record details worked fine and source & destination fields were configured identically. |
CV1-4140 |
When the Import dialog was open, all the other main menu options were still accessible. |
CV1-4135 |
Hyperlinks didn't work in the contextual help texts for fields. |
CV1-4127 |
Dialogue windows didn't always fit the available space in Collections for a minimal screen resolution of 1920x1080 pixels with the Windows scale factor set to 150% and 100% browser zoom. |
CV1-4123 |
ItemNotFoundException was thrown, when clicking the Records featuring keyword button in the Find data for the field window when opened from within a task screen. |
CV1-4119 |
Horizontal scroll bars and numbers in the footer were not available anymore when the mission item screen was resized. |
CV1-4109 |
Error when searching with expand: 'Invalid object name 'collect_rec_stat'.' |
CV1-4107 |
Field properties were not available for fields in table grids. |
CV1-4101 |
Dialogue windows didn't always fit the available space in Collections for a minimal screen resolution of 1920x1080 pixels with the Windows scale factor set to 150% and 100% browser zoom. |
CV1-4100 |
Reverse relation metadata was not copied when copying a record. |
CV1-4096 |
XSLT templates with template type Raw would output text instead of XML. |
CV1-4095 |
When copying field contents using the menu or Ctrl+D from a field group occurrence displayed in a table grid, all occurrences of that field group would be emptied (directly or after pasting). |
CV1-4093 |
Dates stored in forced records were stored in their presentation format, causing data integrity issues. |
CV1-4088 |
Images in HTML fields were not displayed. |
CV1-4084 |
In the link screen for an external thesaurus the detail screen showed incorrect or no data. |
CV1-4079 |
For linked fields, the count function in the advanced search only counted unique occurrences. |
CV1-4070 |
In a specific application, table grids and the Hierarchy browser no longer displayed broader or narrower terms and their merged-in values. |
CV1-4066 |
An Invalid numeric value '4,5' for Field 't4' error prevented a mandatory field to be filled in. |
CV1-4052 |
SAML OKTA generated a Too Many Requests error. |
CV1-4050 |
De auto-complete drop-down for linked fields did not distinguish visually between non-preferred and preferred terms. |
CV1-4040 |
A context field could lead to a screen (and thus the entire record) not being displayed. |
CV1-4034 |
A standard search on Df (description_level) = 'FONDS' in the archive catalogue would freeze Collections. |
CV1-4027 |
For search-and-replace, the Confirm replacement dialogue layout was distorted. |
CV1-4021 |
There was an error when selecting an external thesaurus from the Find data for the field window. |
CV1-4013 |
An error occurred when loading a screen for metadata. |
CV1-4006 |
HTML links in XSLT Inline Reports always had target=_parent. |
CV1-3980 |
A "404 - File or directory not found " error was generated when trying to create a template from the current record. |
CV1-3938 |
The WordCreateDocument ADAPL function did not work in before-storage adapls. |
CV1-3937 |
When exporting using either the Export or the Export to Excel function, the resulting export was not arranged in the expected order of fields. |
CV1-3926 |
One could not select a record in the Hierarchy browser to display it in the detailed view, if that record was already selected in the result set. |
CV1-3861 |
There were severe performance issues, even with simple searches, when using a context field. |
CV1-3815 |
Fields with less text than others on the same line took the same number of lines vertically and unnecessarily spanned many rows when other in-line fields with more text spanned many rows. |
CV1-3794 |
A prompted report did not pass on parameters from the input form to the adapl for an XSLT output format. |
CV1-3772 |
When searching for a specific object via its object number in a specific application, a 504 gateway timeout error occurred. |
CV1-3766 |
When an adapl-only output format contained a pdest 'document.txt' file instruction, the result in the browser was still a pdf file. |
CV1-3765 |
In a linked field, using the Filter button follwed by a Standard search gave an "Unexpected token, expected ')' instead of 'sort'." error. |
CV1-3757 |
A specific Expand advanced search timed out. |
CV1-3754 |
Some metadata reverse relations were not visible in the Related records view. |
CV1-3725 |
Results of an advanced search when using any of the <,>,<=, >= operators for non-indexed numeric fields contained incorrect values. |
CV1-3697 |
Dates assigned via an after-field adapl were not saved in the record. |
CV1-3623 |
In field lists field names were displayed as "data/people/do", "data/people/n4" instead of their English field names if the interface language was Spanish. |
CV1-3597 |
A specific advanced search (OT = *, in an objects data source) returned an error Conversion failed when converting the nvarchar value 'a_status' to data type int. |
CV1-3547 |
Opening the Media Viewer reset the sorting order in the Result set. |
CV1-3512 |
An adapl+Word template could not print an image if the reference came from a FACS record while the FACS database was not equal to the current database. |
CV1-3497 |
In the hierarchy browser, dragging nodes within a node set (reordering siblings) appeared like it was doing something wrong. |
CV1-3493 |
Collections allowed you to save a circular relation within a thesaurus hierarchy. |
CV1-3481 |
The Change Tracking Service had incorrect field mappings to Acquisition number and Acquisition source in OTMM. |
CV1-3425 |
When Collections (or the WebAPI 3.0.20164.1) retrieved an image converted from tif to jpg using "imageformat", then the image was indeed converted but the extension remained .tif, causing a printed image to be printed as a thumbnail. |
CV1-3411 |
Advance searching on a non-indexed date field with the operator <= returned a wrong result. |
CV1-2750 |
A selected record was no longer highlighted in the Result set after editing and saving that record in the Record details. |

2022-07-08: exporting images from records to a zip file
Collections 1.14 has a new option in the Export dialog to export images attached to selected records, to a single zip file.
| 1. | Simply mark the records of which you'd like to export the images (or leave them unmarked if you'd like to process just the current record or all records from the search result). |
| 2. | Click the Export icon in the Result set context toolbar. |
| 3. | Select the new Attached media option in the Format drop-down.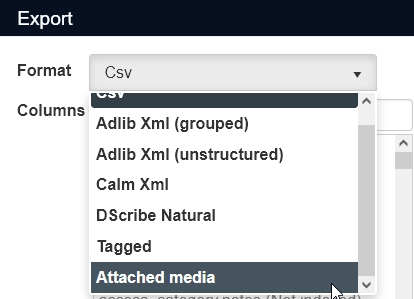 |
| 4. | The field list on the left will now only show the available image fields in the current database: this might only be a single field like reproduction.reference for example. Move the desired ones to the list on the right to export the images linked in those fields. (It doesn't matter if the list on the right contains any non-image fields as well.) If downloading of image files has been disabled for a certain image field by your application manager, then that field won't be available in the list. |
| 5. | Click the Settings button to set your preferences for this export. In the Occurrences drop-down you can select whether you'd like to export all images linked to a record, only the first linked image or only the image which has been marked as the preferred image. For Output format you can choose whether you'd like the image format to remain as they are (Same as the original format) or if you'd like to convert the exported images to some other format: note that the images linked to the records will remain unchanged. If an image file target format conversion isn't supported, the When media is not supported drop-down will become active. Here you can set whether in such cases no format conversion must be applied (Use original file), whether the image must be skipped or if the entire export must be stopped (cancelled). Under Resize you could mark the Export the image to new dimensions checkbox and set desired target values for Width and Height if you'd like the exported images to be resized. The Width and Height will be ignored if the checkbox is deselected. Keep the original aspect ratio must be marked if you'd like the width/height ratio of any exported image to remain the same (even if resized): if you preserve the aspect ratio then the image will be resized to fit within the specified Width or Height specified as much as possible, but the shape is maintained. If you don’t preserve the aspect ratio then the image is stretched in all directions to exactly fill the box specified by the Width and Height. Close with OK if you're done with the settings. |
| 6. | Then select which records you'd like to process, as usual, via the All, Marked and Current radio buttons. |
| 7. | Klik OK to start the export. A progress window appear: wait for it to close by itself. |
| 8. | A media.zip file containing all exported images will now have been created in your downloads folder. |
2022-07-06: copy deep link function
The context toolbars for the Result set view and the Record details view now have an added icon to copy the (deep) link to either the currently displayed record in the Record details view or to the search query or saved search that led to the initial search result displayed in the Result set, to the Windows clipboard to allow you to share that deep link more easily with your colleagues or others.

To copy the link to the currently displayed record, simply click the icon in the Record details context toolbar. Collections confirms the copy action in the right upper corner of the browser window.

Now paste the copied URL anywhere you like (a URL entry field of a new* browser tab, a document or e-mail for example) via Ctrl+V or right-click the document or entry field and select Paste in the pop-up menu which appears.
When copying the deep link from the context toolbar in the Result set view, it always uses the original query that led to the initial search result in this view. If you change the set of records by dropping records or marking them, that does not change the deep link. So if you would like to have a link for a manually changed set of records, then save that set as a saved search first, open the saved search in the Result set, copy the deep link and share it.
For an existing saved search the same applies. First open it in the Result set, then click the Copy deep link icon in its toolbar to copy the saved search link to the clipboard. If the saved search is changed before other users click the deep link, they will just get to see the new contents of the saved search, as the deep link refers to the saved search, not to individual records.
* Note that you shouldn't paste a copied deep link into a browser URL entry field if that tab is already running the Collections application because then it won't work. So always use a copied link in a new browser tab. When a user clicks on a Collections deep link in an e-mail or document, then the link will always be opened in a new browser tab automatically.
2022-06-03: standard searching with "Starts with" operator
From Collections 1.14 it is possible that your application manager has implemented so-called Full Text indexes in your database. For you as an end user, this means an increase in search performance in long text fields, fields with non-unique terms and linked fields plus the new ability to use the Starts with operator in the Standard search.
The operator is present for access points on all text fields, but is especially handy for long text fields like title fields because it allows you to search on the first word the field contents, whereas “equals” would search for the key anywhere in the field. It also implicitly truncates the search key (although it doesn’t hurt if the search key is explicitly truncated). So searching on:
starts with littl
is the same as searching on
equals littl*
as far as truncation goes, but the first query only finds records in which the searched field contents start with the partial key littl while the second query also finds records in which the searched field contents contain the partial key littl at any position.
2022-06-03: real phrase searching
From Collections 1.14 it is possible that your application manager has implemented so-called Full Text indexes in your database. For you as an end user, this means an increase in search performance in long text fields, fields with non-unique terms and linked fields plus the new ability for real phrase searching in such fields via the Standard search (not via Advanced searching yet).
Phrase searching means that you can search a field on multiple search keys (case-insensitive) in the particular order that you provide them, not in any other order. So, for example, if you'd like to search for records which have the phrase "dollhouse with furniture" in the object title, you would select the new contains phrase operator behind the Object title access point and enter dollhouse with furniture in the entry field, before you click the Find button. You may find records with object titles like "Wooden dollhouse with furniture and lights" or "Dollhouse with furniture", but not titles like "Dollhouse with plastic furniture".
Note that for this type of search you cannot truncate any search keys explicitly nor are any search keys truncated implicitly, so you will search on the exact phrase as you've entered it.

Besides the contains phrase operator, there's the opposite one too: does not contain phrase. So if you're looking for records which do not contain the exact phrase provided in the searched field, use this operator: you will still find records in which the field contains the search keys in a different order though or in which none or just some of the entered keys appear.
Note that the normal database structure (without full text indexes) only allows Contains phrase and Does not contain phrase searching on Text (term) indexes, not on Free text indexes for long text fields like Notes and Description.
2022-05-25: XSLT 3.0 support added
XSLT stylesheets for inline reports and output formats now support all functions included in XSLT version 3.0 and earlier. This means that more advanced stylesheets for these purposes can now be made.
2022-05-20: Exporting images to Excel
As soon as you've marked records in the Result set, you can export them to an .xlsx (MS Excel) file by clicking the Export to Excel icon. The fields which are currently being shown as columns in the Result set view, will be the exported fields. Normally, all occurrences of a repeated field will be exported and will end up in a single cell, separated by hard returns.

The exception used to be images: although the reproduction.reference column in e.g. object records displays thumbnails, the exported data would contain the media references, not the images.
This has changed in 1.14. Now the Excel export will put the first linked image of each record in the Excel sheet, using the Thumbnail size as set in the Result set settings. Of media files that do not have a thumbnail (like movie or music files), a standard icon indicating the media type will be exported.

2022-05-19: export and import of the (Adlib) Tagged format
As many Adlib for Windows customers have embedded the use of the ADLIB Tagged file format in their business processes, a migration to Axiell Collections is easier if that format is supported by Collections too. So from 1.14, the Tagged format (identical to the old ADLIB Tagged file format) is available for export and import in Collections too and it's best used only to ease that migration because CSV and XML really are better formats for exchanging data. Most Tagged functionality has stayed the same, but irrelevant options have been left out and of course it looks a little different.
The Tagged format
This format consist of a list of field tags, each tag followed by a space and the field value. In case of repeated fields the tag is repeated for each occurrence. Empty occurrences will be exported too. The records are separated from each other by two asterisks. Of linked fields only the resolved (visible) value will be exported, so the creator name in tag VV from an object record for instance: link reference tags and their values (the record numbers of the linked records) won't be exported, even if you select them. This may pose a problem when you import a non-unique value into a linked field as the import will just look up the first matching value in the index and will link to it, but this was no different in Adlib so that functionality remains the same: best try to avoid importing values into linked fields for which values needn't be unique.
Two books records with a repeated field, exported as Tagged may yield the following file (with the .dat file extension), for example:
%0 29
ti Great Zulu commanders
ex 70
ex 71
au Knight, Ian
**
%0 718
ti The very sleepy pig
ex 1823
ex 1824
ex 1825
ex 1826
au Malam, John
**
Of multilingual fields, only the field value from the current data language will be exported (and occurrences which do not have a value in the current data language but do have values in other data languages will still be exported as empty occurrences), so we recommend using an XML format instead to export all translations and also include language information. When importing a value (without language attribute of course) from a Tagged file into a multilingual field in Collections, it will get the current data language attribute.
GeoLocation fields can be exported and imported as place names. GeoJSON fields can be exported but cannot be imported. These two field types are not Adlib compatible anyway.
RTF (Rich Text Format) fields exported from Adlib to ADLIB Tagged file export all RTF codes along with the field contents. In Collections compatible applications, no RTF fields occur anymore so if you import such fields, the RTF codes will be imported as normal field contents!
Exporting to the Tagged format
| 1. | In Collections, first search a data source for the records you'd like to export and mark them. Then click the Export icon in the Result set context toolbar to open the Export dialog which you may have seen before. |
| 2. | From the Format drop-down select the Tagged format. |
| 3. | Now select the fields to export as you would normally do. If you want the record numbers to be included, be sure to select the priref field. There's no use in trying to export fields of which the name ends with .lref: these won't be exported. To export the complete records, just select all fields and add them to the fields list to export. You select all fields by clicking the first field in the list on the left, then scroll down to the last field, hold the Shift button down and click the last field. Now all fields are selected, so click Add to add them to the field list on the right. It doesn't matter that the list includes .lref fields or other fields you never use: those won't be included in the export file. |
| 4. | Click OK to start the export. The export file name will be formatted like export(#).dat, where # is a number and the file will be saved in your Downloads folder. You can always copy that file from there and rename it as you like of course. |
Contrary to Adlib, there's no means to save your export settings in a parameter file or profile, so you can't use earlier created Adlib parameter files.
Importing from the Tagged format
| 1. | In Collections, click the Import option in the main menu on the left. |
| 2. | You'll have to select a data source to import into, as usual, after which the Import dialog opens. |
| 3. | Select Tagged as the Format, choose the File you wish to import and select the fields to import (only those will be imported). If you include the priref field in your list, it still won't import because Collections will assign a new record number to the imported records, but if you also marked the Update only option and you've set the priref field as the Match field (because you want to update existing records) will the priref in the imported file be used to find matching records. For an update import, the Match field doesn't even need to be in your selection list, but it doesn't hurt if it is. |
| 4. | Make any other settings as desired and click OK to start the import. |
You can't load earlier created Adlib parameter files into the Import dialog in Collections but you can save your import settings in a new Profile.
The Adlib for Windows Process external links and Process internal links options (marked by default) are not present in Collections because they are actually rather advanced options which most users should never switch off. In Collections, external and internal links will always be processed, which means that Collections tries to find a record in the linked database matching the imported linked field value (the first one it finds) and then creates the link to that record. If the imported linked field value doesn't exist in the linked database, a new linked record with the candidate status and the proper domain for the linked field will automatically be created and the link to that record will be established.
Note that of enumerative fields, the user-friendly translation in the current interface language will be exported and that to import this value the interface language must be the same. Adlib exported the neutral (interface language independent) value though, but Collections can import such neutral values too, so enumerative fields in export files created in Adlib will be imported in Collections without problem.