Notes de version 1.11

Contents
The Microsoft .NET Framework Runtime version 4.8 must be installed on the IIS server running Collections (after which the server needs to be rebooted). Ask your system administrator if this still needs to be done.
New options and functions for Axiell Collections make further use of Adlib for Windows impossible
Some of the new functionality introduced in this version and previous versions of Collections requires to be set up by your application manager (as indicated per topic in the various Collections release notes), using new options in Axiell Designer. Since development of Adlib for Windows has ceased quite a long time ago, these new options are not supported by Adlib for Windows. Even if Adlib would ignore the relevant option, you could no longer reliably work in Adlib too, so altered applications using Collections-only functionality should never be opened in Adlib again.
New Collections online Help
The current English version of the Collections online Help you see before you, has been revamped and moved to a different URL: http://help.collections.axiell.com/, although it won't contain these release notes just yet and is still a work in progress. To have your Collections application open that new version automatically, your application manager will have to make a simple change to the Collections settings.xml file: almost at the top of that file, the <Help>http://documentation.axiell.com/alm/collections/</Help> reference (which points to the current version) should then be replaced by <Help>http://help.collections.axiell.com/</Help>. After recycling the application pool, clicking the Help button in the main toolbar on the left, will open the new Help version if you're connected to the internet.
Note that the new version will only be present in English for now. If you make the change above and you click the Help button, you will always be redirected to that English version, regardless of the interface language currently active in Collections. Since the current Collections online Help is available in Danish and French too, users in those language regions are probably better off leaving the <Help> setting as it is, as this will still allow you to use the Help in your own language.
2021-09-21: release notes Axiell Collections 1.11.2
Bug report no. |
Short problem description |
CV1-3464 |
The advanced search expand operator returned an Object reference not set to an instance of an object error. |
CV1-3443 |
Invalid field data (yyyy-mm-dd) in database 'research', record 0, tag 'do', occurrence 1. Use format dd/mm/yyyy error appeared when assigning an ISO date to an ISO date field with the European presentation format from within a task adapl. |
CV1-3416 |
Saving a record with an indexed link configuration could take very long. |
CV1-3408 |
When for an ISO date field the presentation format was European (dd/mm/yyyy), you could still enter non-valid European dates (like American dates (mm/dd/yyyy)) without getting an error and the American date would automatically be converted to a European date. |
CV1-3400 |
Multiple fields in a row, with their labels above them, could be displayed too narrow, not filling out the entire horizontal space, if the data dictionary field length of those fields was relatively small. |
CV1-3399 |
An HTML field did not display its label text as assigned to it via the field's properties. |
CV1-3397 |
If there were multiple HTML fields underneath each other in a single group, they would be diplayed in the right half of the Record details view, instead of taking up the full width of that view. |
CV1-3395 |
When you hovered the mouse cursor over a row in the Manage saved searches window, the row started flickering. |
CV1-3394 |
After editing the contents of an HTML field, you had to leave the field for the Save button to become active, while this was not needed for other edited fields. |
CV1-3392 |
It was not possible to import data into metadata fields. |
CV1-3380 |
Export of specific record resulted in error Collection modified; enumeration operation may not execute. |
CV1-3371 |
After trying to revert a drag/drop operation in the Hierarchy browser - that is, dragging the record back to its original place - an Object reference not set to an instance of an object error appeared and prevented you from dragging other records to the same spot. |
CV1-3370 |
After the Hierarchy browser refreshed from a drag/drop operation, highlighting behaviour was inconsistent. |
CV1-3364 |
Field occurrence suppression conditions hiding the first field occurrence, accidentally hid all field occurrences. |
CV1-3355 |
Right-clicking a media reference field in display or edit mode generated an internal server error. |
CV1-3345 |
Searching for records containing a circular reference could crash the Collections application pool. |
CV1-3343 |
The Disable download property was available for application fields but didn't actually disable the download icon or the possibility to download a file via the underlined link. |
CV1-3340 |
The DashboardVisible setting in the web.config file defaulted to false after installation of Collections. This setting (which is used to enable the Workflow screen directly after logging into Collections, if Workflow is part of your application) has now been moved to the settings.xml file for Collections. It’s part of the <SessionManager> section to keep it as close to the applications settings as possible: <Setting Key="DashboardVisible" Value="true" /> When the DashboardVisible key is not there, the dashboard will not become visible (the same goes for setting the key's Value to false). The setting in the web.config file has been deprecated. |
CV1-3338 |
A WHEN advanced search on a truncated ISO date didn't work. |
CV1-3337 |
An advanced search on a field with a hyphen in the field name resulted in an invalid search expression. |
CV1-3336 |
The Selection list format string can be used for normal linked fields too, but when saving a selected term it went wrong. |
CV1-3335 |
Digital fiels could still be downloaded from fields for which the Disable download option had been set. |
CV1-3329 |
A certain field was no longer visible after resizing the Record details view. |
CV1-3321 |
(In specific application:) new container records were not linked to a new carrier record following the process of an after-edit adapl procedure. |
CV1-3318 |
Field group occurrences which are removed by a storage adapl, came back after storage (or were not removed in the first place). |
CV1-3315 |
Text fields could become truncated in height. |
CV1-3314 |
After setting the Record details Group mode to Paged for table grids for linked fields, the cursor would move up and down the page by itself. |
CV1-3298 |
Numerical values with decimals in UI language Dutch were displayed without decimal character and any the storage adapl doing calculations on those values didn't see the decimals either. |
CV1-3274 |
There was a screen rendering issue with a single (date) field wrapping to the next line. |
CV1-3266 |
Uploading 20+ images to an object record was failing and gave an internal server error. |
CV1-3226 |
Export of specific record resulted in error Collection modified; enumeration operation may not execute. |
CV1-3211 |
Having performed a search using the sort operator, the Result set could not be re-sorted. |
CV1-3129 |
ONSOP in a secondly executed output adapl used the texthandle from the firstly executed adapl, instead of the newly assigned texthandle in the second adapl. |
CV1-3123 |
The right-click Properties option for a date field didn't display the stored date in the field if it wasn't an ISO date. |
CV1-3120 |
On the Saved searches tab in the Search window, the Show, Delete and Schedule buttons were not greyed out when no saved search had been selected yet. |
CV1-3018 |
In the properties of a field, no screen name is visible, only the string "expression". |
CV1-2893 |
The Parts field already visible in the Record details view was not automatically updated after drag-and-drop or bulk create operations in the Hierarchy browser. |
CV1-2823 |
Deriving records using a saved search was not possible. |
CV1-2658 |
An Unresolved link in ‘document’ for record 500001989, ex[2]=1000167610, domain='' type of error could appear in a specific application when creating a new copy record from within a book record. |
CV1-2561 |
If a single field was copied to the Collections clipboard, and you attempted to paste it within the same record and field (even in a different occurrence) then nothing happened. |
CV1-2535 |
Storing a saved search for many records, say tens of thousands and more, could take a very long time. Also adding extra records to such a saved search or removing records from it, took very long. |
CV1-2510 |
When you had marked the Add new occurrence option in the Search and replace window, the Match entire field, Match whole word and Match sub strings options would not be greyed out. |
CV1-2468 |
The Rights tab for a selected saved search in the Manage saved searches window, showed $ADMIN in the roles list multiple times. |
CV1-2384 |
When manually assigning a number to a saved search, the saved search was not saved. |
CV1-2085 |
It was possible to have the Use (tag us) and Used for (tag uf) fields in a thesaurus record both filled in. |
2021-07-12: release Axiell Collections 1.11.1
Bug report no. |
Short problem description |
CV1-3333 |
Clicking a metadata enumerative field caused the cursor to turn into a spinning wait symbol. |
CV1-3313 |
A truncated search on ISO date no longer worked. |
CV1-3305 |
Inheritance in repreatable groups didn't work properly. |
CV1-3303 |
Thumbnails in were not shown in the Result set and Media Viewer if they were retrieved using the WebAPI. |
CV1-3302 |
Searching on a free text method on a metadata field returned a Conversion failed when converting the nvarchar value '...' to data type int error. |
CV1-3301 |
There was an error on opening a specificly designed screen tab. |
CV1-3297 |
Searching a metadata enumerative field was not returning any results. |
CV1-3295 |
Right-justification in screen fields wasn't working. |
CV1-3293 |
Of a table grid for a linked field group, some fields were displayed outside the grid. |
CV1-3292 |
An internal server could occur when trying to add two new records in a row, in a specific data source. |
CV1-3289 |
Certain inherited data did not display in display mode, but did display in edit mode of a record. |
CV1-3285 |
An after-field adapl wouldn't run if the associated field was displayed in a table grid. |
CV1-3284 |
If a write-back field was filled by a before-storage adapl, its value was cleared when the record was saved. |
CV1-3282 |
Fields in a field row on a screen, which did not belong to the field group of the other fields, were hidden instead of displayed on the next line. |
CV1-3281 |
Using drag and drop in the Hierarchy browser to change the order of the narrower terms or to move them to a different parent did not work. |
CV1-3280 |
The does not equal operator in Standard search could not be used in combination with a selected Expand checkbox, without giving errors. |
CV1-3279 |
If a link reference tag was not part of the field group that its associated linked field belonged too, adding a new field group occurrence would result in faulty behaviour. |
CV1-3276 |
Metadata search functionality was not prepared for returning catalogue records more than once in the same search result: this would give a "non-unique" error. |
CV1-3275 |
Calling borrower (.inf) as a FACS database gave an error 55 because setting a default value for a date field failed. |
CV1-3272 |
$role conditions were not recognized when the user had several roles. |
CV1-3268 |
Searching on all and not edit.name = erik didn't work, because edit.name was a non-indexed field. |
CV1-3267 |
There was a problem with advanced searching on fields P2 and SN in Workflow. |
CV1-3263 |
There sometimes was an error Invalid column name 'retrieved' when opening the Advanced search in applications on the hosting server. |
CV1-3262 |
Screen suppress conditions which contained more than one field didn't work as expected. |
CV1-3259 |
Bulk create didn't work for the Object catalogue, when an object name was entered. An error was null or empty in database incoming Parameter name: tag was generated. |
CV1-3254 |
After entering data in a field and clicking another field, the cursor jumped back to the previous field. |
CV1-3246 |
After emptying metadata fields in the last field group occurrence in a table grid and saving the record, the metadata came back. |
CV1-3243 |
An internal sever error occurred when creating a new object record in a specific application. |
CV1-3242 |
It was possible to delete a saved search even though its access rights had been set to read-only. |
CV1-3239 |
The Result set filter for lender Name in the Incoming loans only contained the option Undefined. |
CV1-3238 |
Certain simple export jobs for several thousands of records took way too long to finish. |
CV1-3237 |
Default values for repeating fields were not populated when an occurrence was created while the relevant field had the focus. |
CV1-3236 |
If a field was suppressed, blank spaces were being left until the start of the next field that was not suppressed. |
CV1-3235 |
Uploading media in new records no longer recognized the configured folderId (for Enterprise applications). |
CV1-3234 |
Linked metadata was not searchable. |
CV1-3230 |
The Related records view was not working properly for reverse relations. |
CV1-3229 |
If a link reference tag was not part of the field group that its associated linked field belonged too, moving a new field group occurrence up resulted in faulty behaviour. |
CV1-3227 |
When filtering on a record in a result set, the selected field did not refresh in the Record details view. |
CV1-3223 |
Workflow records didn't display anymore. |
CV1-3221 |
When an import was running and the user opened the Scheduler, you could click the Details button but it produced an empty pop-up message. Only when the job was finished would the Details button provide information. |
CV1-3218 |
Invalid field data (yyyy-mm-dd) in database 'research', record 0, tag 'do', occurrence 1. Use format dd/mm/yyyy error appeared when assigning an ISO date to an ISO date field with the European presentation format from within a task adapl. |
CV1-3214 |
Object reference not set to instance of object error occurred when printing to an output format consisting of a Word template, an adapl and a parameters screen. |
CV1-3213 |
A method on a metadata field returned: Invalid column name 'priref'. |
CV1-3189 |
Location history merged-in data didn't display and the screen wasn't respecting field grouping. |
CV1-3184 |
Linking objects to a specific custom data source failed and any existing links to the data source were dropped at the same time. The issue was specific for non-repeating linked fields in combination with the bulk link feature. |
CV1-3183 |
A screen box suppress condition was not honoured when creating a new record. |
CV1-3181 |
Searching linked enumerative fields no longer worked. |
CV1-3173 |
If you uploaded an image via a linked image field and subsequently clicked another field, then the cursor would repeatedly jump between the image field and the other field. |
CV1-3172 |
Boolean "OR" searches like Df = 'FONDS','SUB-FONDS','SERIES' only found records for the first search key, 'FONDS' in this case. |
CV1-3171 |
Selecting a term from the Find data for the field window overwrote the first occurrence of the relevant linked field if it was an ungrouped linked field, while the second occurrence was also filled with the selected value. |
CV1-3169 |
Tif media files woul no longer display a DAMS ingested jpeg rendition for a thumbnail. |
CV1-3167 |
A Result set view page (part of the list) containing an invalid record (with a multilingual attribute in a mono-lingual field) was not shown at all. |
CV1-3166 |
Sorting records in metadata tables did not work. |
CV1-3164 |
Incorrect resulting hierarchy after dragging and dropping records in the Hierarchy browser. |
CV1-3162 |
After copying or creating a record and trying to save it, for some records an "Object reference not set to an instance of an object" error appeared. |
CV1-3156 |
Clicking the Save icon didn't work in some data sources. |
CV1-3154 |
Values could not always be read from or written to metadata fields from within an adapl. |
CV1-3152 |
On some customized screens, text fields like Title etc. were so narrow that the line break already occurred after 3 or 4 characters. This made the field illegible. |
CV1-3151 |
The error message: The current SynchronizationContext may not be used as a TaskScheduler was always thrown when you tried to update existing records (Match field = priref) during an import. |
CV1-3142 |
It was not possible to delete a metadata relationship when a record was linked twice. |
CV1-3140 |
PDF, .xlsx and .docx files could be opened and downloaded from an application field with a relative path in the data, but not .doc and .msg files. |
CV1-3137 |
Invalid date values in a table grid could not be corrected. |
CV1-3132 |
An adapl generated URL didn't open after being clicked, unless the record was edited first. |
CV1-3126 |
Linking articles through Links option on a loan, linked those articles to the loan but also to an accession record. |
CV1-3105 |
The ADAPL function OPENURL got Collections in an endless wait state. |
CV1-3083 |
Adding a new row to a field group with a linked field in a table grid, would not scroll down to the new row of if the maximum numbers of rows was already displayed you had to scroll down manually to find the new row. |
CV1-3064 |
Dependency rules were bypassed by pointer file linking, so records could be linked that way even though the hierachical depency rules should have prevented that. |
CV1-3023 |
Deleting linked fields with backwards references only deleted one side of the link. |
CV1-3001 |
Field read only conditions wasn't applying restrictions for the $role parameter. |
CV1-2995 |
Default values for fields "included" in a dataset were not populating. |
CV1-2986 |
A merged-in Title field in a specific Word template was not filled when printing to it. |
CV1-2985 |
Clicking on a link in a specific application field returned an error: Failed to read media item ... not allowed to go above... followed by a path. |
CV1-2976 |
If for import an update field was set that wasn't present in the exchange file, then new records were created even if Update only was checked. |
CV1-2975 |
A reverse link did not display in the linked database. |
CV1-2956 |
Collections ignored the Exchangeable setting in "included" fields in datasets. |
CV1-2955 |
The reverse link of an inheritable field created a new occurrence with the current record as the child record in the parent record in the linked database. |
CV1-2941 |
Double validation on linked fields used the format string as a new term instead of the term itself. |
CV1-2939 |
The Show candidate terms checkbox had gone missing in the Thesaurus. |
CV1-2909 |
A table grid field group which contained write-once fields didn't display any field data. |
CV1-2908 |
Adapl error messages from before-storage procedures were not displayed in the Hierarchy browser. |
CV1-2879 |
Field tags consisting of two digits led to an error: Invalid report field expression '' in template. |
CV1-2865 |
A merged-in enumerative value wasn't displayed if the relevant neutral value was not defined in the destination field. |
CV1-2829 |
Browsing through records in the Hierarchy browser only refreshed an image in the Media Viewer if the record you clicked was already in the original search result. If not, it would not refresh the Media Viewer. |
CV1-2817 |
Using a year filter on a date field column in the Result set didn't work. |
CV1-2778 |
Adapl-only output formats did not handle diacritcs correctly. |
CV1-2768 |
Uploaded files in the ..\collections\App_Data\FileCache folder could cause Collections to crash as start up. |
CV1-2763 |
When you right-clicked a linked field, the pop-up menu overlapped the automatically opened auto-complete list. |
CV1-2658 |
Before-storage automatic numbers were only assigned to the first occurrence of a field. |
CV1-2642 |
Searching sometimes gave a State not found error when the Media Viewer was active. |
CV1-2638 |
The Record details view did not refresh after the Result set was filtered and no longer contained the record displayed in detail. |
CV1-2445 |
An internal server error was triggered when the GeoJSON map (using the map icon in the Record details) was loaded. Seconds later, the session would expire abruptly. |
CV1-2442 |
Searching on a non-indexed field with the Contains operator returned an error: The method or operation is not implemented. |
CV1-2428 |
After adding a certain date field as a column to the Result set view, the column would show empty even though there was data in the field. |
CV1-2364 |
When you edited a field in a record and then navigated to another record via the Hierarchy browser, there was no prompt to save the changes. This would only happen if you didn't leave the field you had changed when navigating to another record. If you clicked another field first before navigating away, the prompt did show. |
CV1-2345 |
For the Requester field in Outgoing loans, the Find data for the field window contained no found terms and the Show candidate terms checkbox was missing. |
CV1-2339 |
If the overarching folder for multiple application folder had been specified as the application folder for Collections, no background image was displayed in Collections after logging in. |
CV1-2335 |
The New, Search, Interface language, Data language, Import, Help and Account options in the main menu on the left weren't accessible by tabbing through all buttons, icons and record fields. |
CV1-2314 |
Help text was always cut off on the right side of the Help view. |
CV1-2239 |
The Gallery view Settings window title was Result Set settings. |
CV1-2040 |
The Related records view did not show the correct data sources for internal links. |
CV1-1942 |
The storage adapl for a reversely linked database was not executed when a record in that database was updated through the reverse link. |
CV1-755 |
The Save icon didn't work after adding an occurrence to a field group in a table grid. |
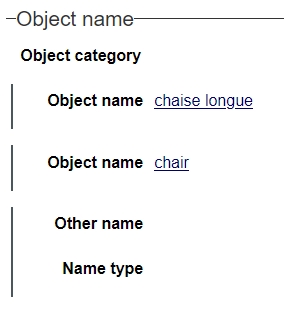
2021-07-01: Visual field groep occurrence distinction
Field group occurrences are now indicated by a vertical line in front of the first field, to make it easier to see which fields belong the same field group occurrence. So below you can see two field group occurrences of the Object name field group and one of the Other name/Name type group.
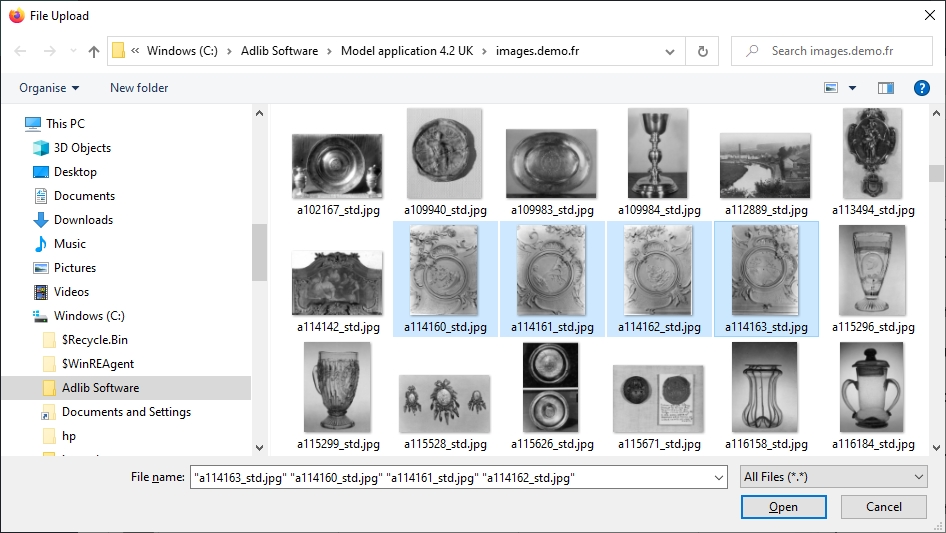
2021-06-21: uploading multiple media files at once
Collections 1.11.1 allows you upload and link multiple media files to an image or application field at once, whether you are editing a Multimedia documentation record or a catalogue record. The only condition is that the media field is repeatable: in non-repeatable media fields you can only link a single media file.
So here's how it works:
| • | After you've clicked the upload button next to a repeatable image or application field, you can now select multiple files to upload in the File upload window. To select multiple files in a row, just click the first file, press Shift and keep it pressed down while clicking the last desired file. To select files here and there, click the first desired file, press Ctrl and keep it pressed down while clicking the other desired files one by one. Then click the Open button to upload the files. |
| • | Each uploaded file will end up in its own field occurrence. It matters which existing media field occurrence currently has the focus (where the cursor is). The linking of uploaded files will start in the active field occurrence. If that field occurrence already contains data, that data will be overwritten with a new link! Subsequent existing media field occurrences will not be overwritten but will move down to accomodate for the new links. So, for example, if you already have three image field occurrences A, B and C with the cursor in B and you upload image files G and M, then what remains is four occurrences A, G, M and C. |
2021-05-07: release Axiell Collections 1.11.0
Bug report no. |
Short problem description |
CV1-3050 |
When navigating a record in edit mode in the Record details view using the Tab key, and then opening a closed tab by pressing Enter, the view would scroll back to the top of the record instead of staying were it was. |
CV1-3047 |
In specific cases, an Ambiguous datasource error could appear after marking a checkbox to run an after-field procedure. |
CV1-2997 |
Time fields did not accept a time in the hh:mm format (without seconds). |
CV1-2982 |
With specific Numerical field properties set for a numerical field, numerical values were stored incorrectly in the XML: the presentation format was stored. |
CV1-2963 |
Some record access rights restrictions were not working. |
CV1-2957 |
Standard search statements with the operator does not equal combined with Expand generated an error like: Field name 'not' not found in 'collect', dataset 'film |
CV1-2942 |
When records with specified rights had been set for a role to read-only, then the user assigned to that role was still able to edit said record. |
CV1-2938 |
There was a long lag when the Record details view was loaded while all screens were open. |
CV1-2931 |
Storage adapls would evaluate a check on whether a tag was empty as true, while the tag was actually filled. |
CV1-2916 |
Images retrieved via the WebAPI were no longer printed to reports. |
CV1-2914 |
Output template type Custom: ADAPL reserved variable &I wasn't filled correctly: for the first processed record, &I was zero. |
CV1-2898 |
Export was resolving the full record instead of only resolving what it needed (namely the selected fields to export), so even if certain linked fields weren't selected for export, these were resolved anyway, causing slow performance if the record contained many links. |
CV1-2892 |
Default multilingual values for linked fields were no longer automatically filled in because the multilingual link resolving failed. |
CV1-2877 |
An error message from a storage adapl was displayed twice. |
CV1-2876 |
The adapl reserved variable &1[3] had the wrong value "1" when writing a new linked record (should be "2"). |
CV1-2875 |
Under some specific conditions, when a record contained a multilingual field with data but also with a trailing empty data language attribute, it was possible that data was lost when writing the record. |
CV1-2874 |
Error Invalid column name 'Creation' when searching the database in a specific application. |
CV1-2858 |
If you edited a record by changing the value in a single field and then clicked the Edit mode icon without having left the field, then Collections did not ask if you wanted to save your changes and closed the record without saving. |
CV1-2857 |
If you were not the owner of a record and you set the User/Group Rights to be Read only, then anyone could still edit all the fields in the record, including the owner. The only fields that could not be edited were User/Group and Owner. In addition, if you tried to add different Rights for different users, then when you saved the record, an internal server error occurred for the User/Group field. |
CV1-2853 |
Of conditionally hidden fields in table grids, the column header was still visible even though the data was hidden. |
CV1-2849 |
Auto-generated enumerative lists were not populated if the filtering field was manually entered rather than selected from the Find data for the field dialog. |
CV1-2845 |
In very specific circumstances, inherited values could disappear from a record after an edit. |
CV1-2844 |
Table grids wouldn't always display data consistently. |
CV1-2842 |
When using the Copy field function for an "included" linked field, the value was copied without its link reference, so when this value was not unique in the linked database and you pasted the copied field, the newly created link could link to the wrong record (with the same value). |
CV1-2826 |
Recent edit data would not show up, if the edit details field group on the Management details tab had been turned into a table grid. |
CV1-2815 |
Collections would throw file not found exceptions on adlib.json, mission.inf and other schema files. |
CV1-2812 |
Field tags on screens which hadn't been specified in the data dictionary caused Collections to run into problems and you had to log out and log in again. |
CV1-2808 |
Using the search-and-replace function to add occurrences of data to fields that are also inheritable, to multiple records within a hierarchy, resulted in extra occurrences with the same data to be created, and sometimes the initial occurrence inheritance got lost. |
CV1-2807 |
In the Import window, the name of the last selected profile would display between brackets in the title bar, even if it wasn't selected at that moment. |
CV1-2806 |
When in the Results set display, adding the Level column (field record_type (Df)) to the grouping bar didn’t produce the expected results. |
CV1-2804 |
Column filters in the Result set were reset after saving a record. |
CV1-2802 |
It was not possible to scrub (fast forward or rewind) through a video file in Google Chrome and Microsoft Edge browsers. |
CV1-2797 |
When a Result set field depended on a suppress condition, but the condition used field names rather than tags, then the Result set view would report TagNotFoundExceptions in the log. |
CV1-2789 |
With the SQL database collation set to a certain complex character set, errors like Cannot resolve the collation conflict between "SQL_Latin1_General_CP1_CI_AI" and "Latin1_General_100_CI_AI" could appear when opening the Saved searches. |
CV1-2788 |
The Advanced search field list did not include the record number (priref) field. |
Cv1-2784 |
The metadata table was not cleaned up when in the data a relationship was removed. |
CV1-2780 |
A Could not find stored procedure 'dbo.ac_pfile_get_page_v1' error could occur in the Axiell SaaS environment because the initialization of the stored procedures was going wrong. |
CV1-2779 |
After retrieval adapl procedures were not executed. |
CV1-2769 |
No “This Record is already locked by someone else” message was displayed when trying to edit a locked record in the Result set. |
CV1-2767 |
Before-deletion code in a storage adapl (with an if &1=12 condition) was not executed. |
CV1-2746 |
Searching with a truncated value on a non-indexed field returned an error: the method or operation is not implemented. |
CV1-2673 |
In a specific application, entering data returned an error: The string was not recognized as a valid DateTime. There is an unknown word starting at index 0. |
CV1-2669 |
For interface language English, when using the Validate icon in a linked field (for a field that has a fixed domain), the resulting list of found keys was correctly presented filtered and the option to activate or deactivate the filter was presented, but that filter option was not present for other interface languages and then the results were unfiltered. |
CV1-2641 |
Add row below in a table grid for a linked field didn't add the row below the current row. |
CV1-2613 |
When the WebAPI was used to retrieve images in a different format (like with the imageformat=jpg argument) for printing to a Word template, then the format of those images wasn't really converted and the resulting images were printed very small. |
CV1-2575 |
A Retrieval path setting for an "included" image reference field, did not override the Retrieval path setting for that field in the main field list of the .inf. |
CV1-2573 |
Searching using "count" didn't work on linked fields. |
CV1-2494 |
Linked video and audio files displayed broken-link icons in front of records in the Result set and Gallery views (although the files displayed or played fine in the Media Viewer), if no proper thumbnails could be generated. If no file type can be determined either way, now no icon is displayed at all. |
CV1-2486 |
Removing a leading space in front of a term didn't update the DisplayTerm in the SQL table. |
CV1-2482 |
Searching non-indexed fields performed very badly and Collections could stop responding. |
CV1-2424 |
When certain thesaurus terms had a leading space they ended up on top of the search result when you sorted alphabetically (which was and is correct), but when you then removed those leading spaces, those records would still end up on top of the Result set because of an indexing issue. |
CV1-2375 |
After starting a new session, Advanced search set numbers would continue where you last left off, instead of starting at 1 again. |
CV1-2352 |
Searching non-indexed fields performed very badly and Collections could stop responding. |
CV1-2227 |
The Ctrl+N shortcut (meant to create a new record) did not work as expected in Chrome, Firefox and Edge. |
CV1-1959 |
Temporary fields could not be exported. |
CV1-1942 |
Storage and edit procedures for a reversely linked database were not executed when a record in that database was updated through the reverse link. |




2021-05-04: WCAG compliancy and accessibility improvements
The WCAG (Web Content Accessibility Guidelines) were developed by the Web Accessibility Initiative in order to provide a single standard for web content accessibility, to make web content like web pages and web applications (text, images, page structures, etc.) more accessible to people with disabilities.
We at Axiell wholeheartedly endorse this standard, so we are now working towards making Axiell Collections fully WCAG 2.1 Level AA compliant, Collections 1.11 to start with, but ongoing in subsequent, future releases.
Directly after opening a record in Collections 1.11 you'll notice some changes immediately: the font size of record data, field labels and field names in lists has been enlarged for better readability, the light blue background colour in the Record details view has been changed to white, the alternating colours in the Result set have been changed to white and grey and label texts in front of fields are now right-aligned in the label box (instead of left-aligned) to be closer to the data itself.
Now the challenge with Collections was and is that it has to be both responsive (meaning that it has to display well on different devices with different screen sizes (by automatically scaling the size of fields and/or wrapping fields with their labels to the next line) as well as being WCAG compliant, while the screen tabs on which the record details are displayed have been designed with fixed field lengths and precise field and label positions in mind before Axiell Collections even existed.
Still, the accessibility improvements have led to a significant improvement in the responsiveness of the main views and screens in Collections: the Result set view and the Record details view. It’s especially the detailed record view that has gone through a complete revision. The screen formats are now rendered in a new way. While this works very nicely for most screens, it is possible that, especially for customized screens, the presentation of the fields or labels may not be perfect yet. We recommend installing version 1.11 in a test environment first to see if your custom screens look alright. Should you notice something that doesn’t work well, please let us know so we can provide a solution. This could be something we need to address in a new version of Collections but it’s also possible that the affected screen needs adjusting.
To improve the accessibility of the Axiell Collections user interface further, several changes have been made:
| • | The icons in the Media Viewer have been enlarged for better visibility and moved to a better position. |
| • | The quick/simple search drop-down list in the Result set context toolbar has been made wider so that long field names are completely visible too.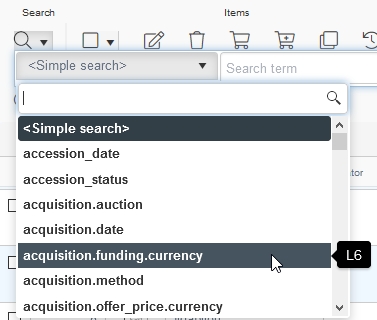 |
| • | In the Occurrence drop-down list in the Record details view context toolbar, the Move field down and Move field up options have been renamed to Move row up and Move row down, to make it clearer that they move an entire row of fields (field group occurrence) if the field is part of a field group. |
| • | Previously there was no quick way to tell which fields in a record in edit mode could hold multilingual data. This is has been improved by removing the Edit multilingual texts flag icon (which was only active in the Record details context toolbar when the cursor was located in a non-linked multilingual field) from that toolbar and by displaying a flag icon on the right side of every multilingual field. Simply click the icon to open the Multilingual data window to edit all translations of the field data simultaneously. |
| • | The box that is used to visually surround groups of fields in the layout has been transformed to a top line style to reduce visual clutter, so instead of a box, only a line above the field group is now visible, containing the box label. |
| • | Fields in Collections can be configured to inherit values from parent records. Prior to release 1.11, these fields displayed in light grey. Now, inherited values display in black with a dotted underline. |
| • | Since Collections 1.10.1, the Result set is always displayed in paged mode. New in 1.11 is that the number of records per page is now dynamically adjusted to the height of the browser window, so that you never have to scroll down anymore to see all records on the page when flipping through pages. Very handy indeed! |
| • | It is possible that certain field groups in your application have been made to display as table grids. Those grids used to have a fixed height with a vertical scrollbar to scroll through all the rows. New in 1.11 is that you can change the height of such grids to your desire, for instance because you'd like the grid to show more or fewer rows by default. To change the height of a table grid, look for the small corner icon (six small dots in a triangle) in the right bottom corner of the grid. It'll be there only in display mode of a record, not in edit mode.  Move the mouse cursor over the icon to have it change to a double arrow:  Then press the left mouse button down and drag the icon up or down to change the height of the grid and let go of the mouse button to fix the height. Only after you release the mouse button, will the grid display the extra records, not during resizing. The new height of this box will be remembered for you by Collections.  |
| • | The View lists tab on the Find data for the field window has been renamed to Saved searches to better reflect what the tab shows, namely a list of saved searches in the linked database. Click a saved search and click the Select button to link all records from the saved search to the current linked field (which should be repeatable). You still get to confirm your action. |
| • | To show the result of an earlier executed advanced search statement (a "set") again in the Result set (without executing the search statement again), you previously had to select it in the Set(s) list and then click the Select set button. To make this quicker and easier for you, you can now just double-click the desired set to open it in the Result set view. |
2021-04-06: more ways to view the Record history

The Record history window, which can opened with the relevant icon (only present if this functionality has been set up for the current database) in the Result set context toolbar, now offers an extra tab called Difference.
The new screen tab offers different ways of viewing the current state (contents) of the records, the previous states and what has changed. Even deleted records can sometimes be viewed.
After entering and saving a new record you can already view its contents. (Set the View to Full with changes each time to follow the examples.) All new data is in green and has a + sign in front of it, meaning this was data that was entered in this record state. The date and time this state was saved, and by whom, can be seen on the left: the green bar (hover the mouse cursor over it to see the tooltip) in front of it indicates that the record was created at that point in time.
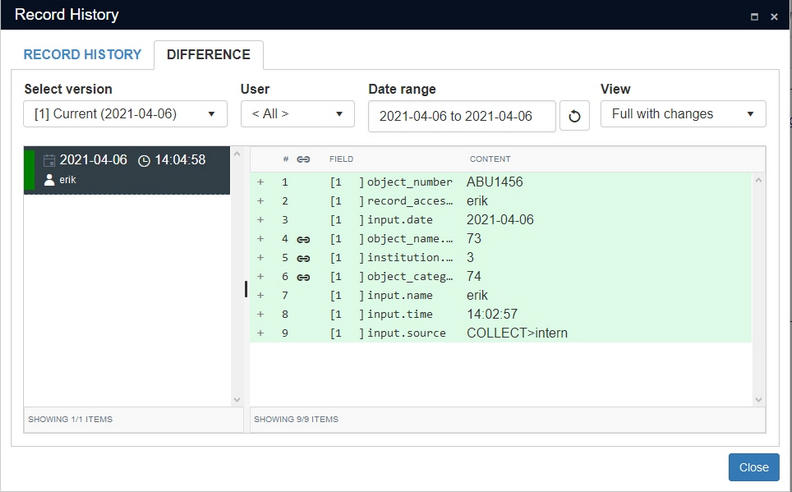
Hover the mouse cursor over a field name to see the field tag in a tooltip.
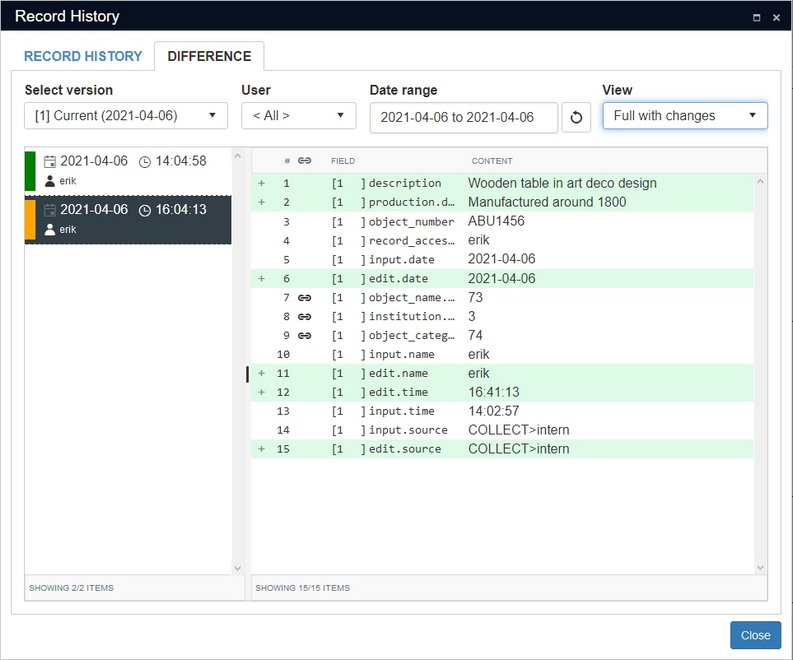
If we now make a change to the record - we add a description and production notes and save it - we can open the Record history again to see a second present state. Click the first one to see the original state of the record and click the second one to view it as it is now. You'll notice the new description and notes are in green because they were newly added and an automatic background (adapl) procedure added the edit details on saving, so those are in green too. The orange bar in front of the name and the date and time of modification indicate that an existing record was modified.
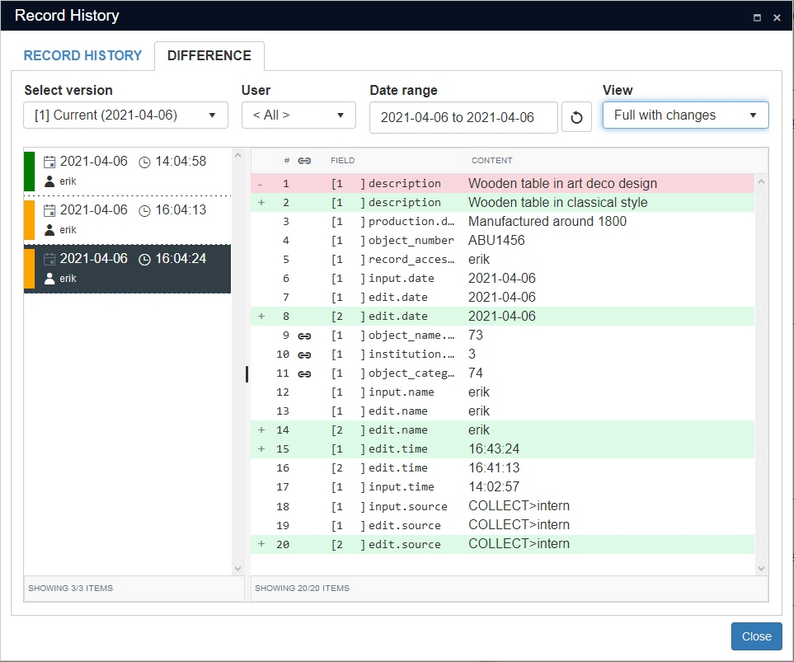
Since art deco wasn't around that early, we need to correct our mistake. After making the change, a third state has become available showing the deleted value in red with a - sign in front of it and the new value just below it, their occurrence number (1) in front of the field name indicating the field occurrence in which the change took place.
Filtering the overview
You'll notice the right window pane is getting a little crowded. We can change that by selecting a different View from the drop-down list. You can of course freely switch views without losing data.
| • | The Full view shows the record state at the selected date and time, without colour-marking any changes. |
| • | Full with changes shows the record state at the selected date and times, while marking changes. |
| • | Compact changes shows the changes in the selected record state and also some unchanged fields for some context, but leaves out most unchanged fields. |
| • | Changes only shows only the changes in the selected record state and leaves out all unchanged fields.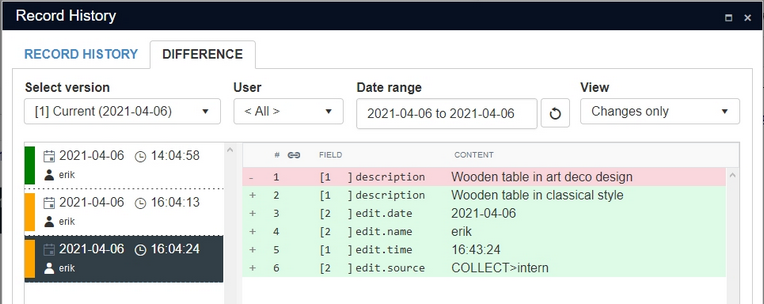 |
Click the Date range box to select two dates between which you'd like to see any record states, leaving out all other states. Always select two dates and then click the blue Close button in the date picker to update the overview. Click the Return icon next to it to return to the previous date range. By default this range is set to the full range available for the current record.
If multiple users are allowed to edit the record, you can use the User drop-down list to decide if you'd like to see changes from all users or just from some specific user.
The Select version drop-down finally usually shows only one record "version", namely the current one, by displaying its creation date and last edit date accompanied by the names of the responsible users.
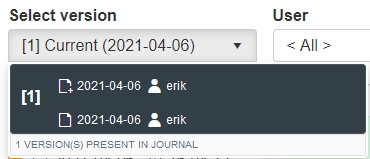
The concept of this list is bit complicated though. Once a record is deleted, its record number becomes available and will be used again once the highest allowable record number in the current dataset has been used. So in that case, when a user creates a new record, it will get a record number of a record that was deleted long ago. Now, this record history identifies records by its record number and it doesn't delete the history of a record when it is deleted... This has advantages and disadvantages. If you open the Record history on the Difference tab and you see a red bar in front of a record state, it indicates that a record was then deleted, but the earlier record states still allow you to see what was in that deleted record! The record state just following the red one should be a green one because that's the record you are currently examining. These re-creations of record numbers with completely new record contents are called "versions" at the moment. So the deleted record was version 1 and the new record with the same number is version 2. If you'd only like to see the record states of one particular version, then you can select that one in this list.
Notes
| • | Of multilingual fields, the applicable language code is displayed in front of the value. |
| • | Of linked fields, only their associated link reference fields are included (indicated by the chain icon) and their value is the record number of the linked record. |
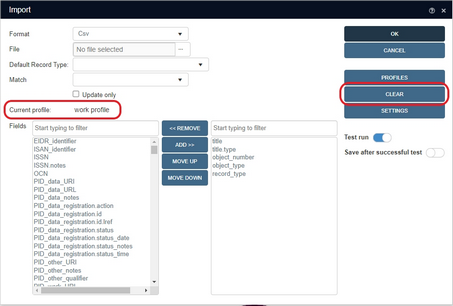
2021-03-30: running Collections import jobs in the background
Collections 1.11 offers the option to have import jobs run in the background. This has the big advantage that you don't have to wait for it to finish (which can take long if the import job is large) and you may continue with other work in Collections instantly. It is currently not possible to have the background import job run at a scheduled time though: it is executed immediately. This does mean that update imports (for which existing records are updated) should only run this way (or the normal way for that matter) if no-one is working in those records during the import, because a record in edit mode cannot be updated by an import job. This limitation does not apply to importing new records.
This functionality is extra and requires Axiell ALM assistance to set up. Please contact our Sales department for more information about how to get it.
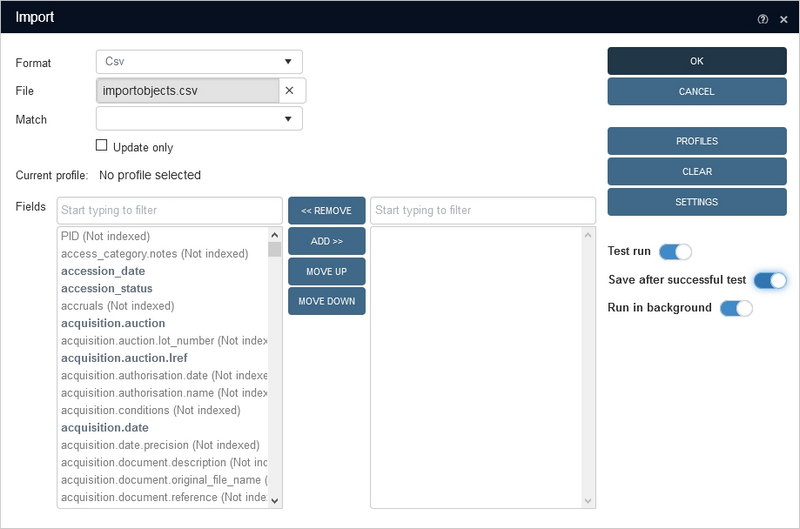
If the background imports functionality has been set up, you'll find a new Run in background slider in the Import window. You may create your import here the normal way. Make sure that you've selected a File, checked the Settings to see if the correct separators and formats are used and decide if you just want a test run without or with saving if successfully tested. Best thing would be to switch both Test run and Save after successful test on, so that only a correct import is actually executed and saved. To run your import in the foreground (as normal), leave the Run in background slider in the left position (switched off), but switch it on (it turns blue) to submit this import job to the special service which executes this import job in the background once you click OK.
Once you click OK in the Import window, a copy of the selected import file will be made and copied to a location accessible to the background service. Also, the following message will appear:

Click OK to close the message.
A new Schedule option (only present if the functionality discussed here is available to you) in the main menu on the left opens the Scheduled tasks window.


In this window you can see the progress and other details of the current and previously executed background import jobs. The Description column displays the original name of the imported file. The Status shows whether the import job is still Running or Done, while the Progress column displays the number of processed lines from the import file so far, but it is not dynamically updated: to update the Progress column manually, click the Refresh icon in the bottom right corner of the list (you can do that repeatedly).
![]()
Note that the final number in the Progress column will always be 2 higher than the number of records in the import file: it counts the first line with the field names and the last empty line too.
The Created column displays the date and time on which you clicked OK in the Import window while Last activity shows the date and time the import job was finished.
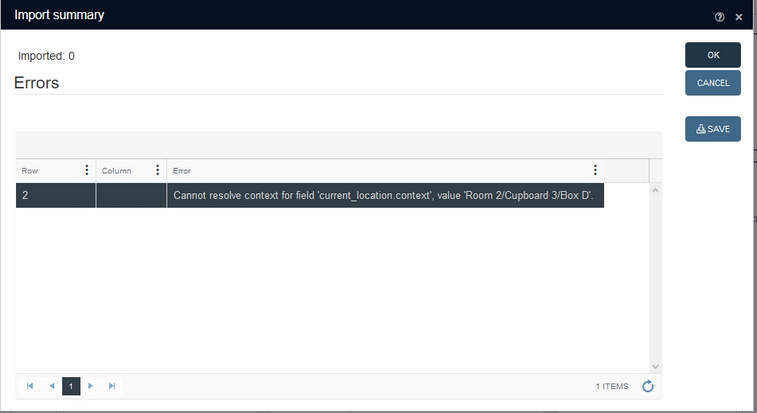
Select any of the listed, executed import jobs and click the Details button to get some extra information. This might just be a message about the number of successfully imported records, but it might also open an Import summary window if errors occurred during import. If Test run was switched on, all the records in the import file will have been processed allowing the Import summary to show all errors present in the file, while if you had switched the Test run off, the import will only run until if finds an error and only this one error can then be shown in the Import summary window: another reason to switch both Test run and Save after successful test on for these background imports. If an import job fails because of incorrect settings (e.g. if the actual field separator in the import file doesn't match the field separator set for the import job), the job Status will become Failed and clicking Details will inform you about the issue.
If clicking the Details button opens a message (instead of the Import summary window), you'll only get to see the first message that was generated, so for example: if you had all three sliders switched on, clicking Details might show a message about how the test run was completed successfully without any information about how many records were actually imported (because that message would be generated later). Of course, you can search your database for a combination of input date and input name for example, to find all imported records.
2021-03-15: storing and using favorites per field
If you often fill in the same texts, terms, names, dates or numbers in certain fields, even linked fields, but you don’t want to have to type them or (in the case of linked fields) select them from the drop-down or Find data for the field... window each time, then you can now store such texts as favorites for that field. This allows you to quickly select that text directly from the right-click pop-up menu for that field next time.
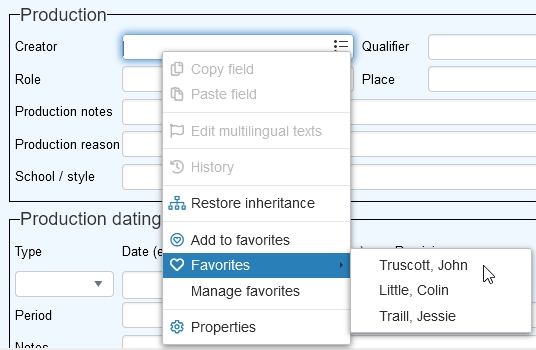
To store a value from a field in the favorites list for that particular field, simply open a record in either display or edit mode, right-click the field value which you'd like to add to the favorites list for this field and select Add to favorites in the pop-up menu. Note that a favorite for one field won't appear in the favorites for other fields and that favorites are saved per user and per application.

Once one or more favorites have been stored for a field, you can quickly retrieve them from the same pop-up menu for the same field in a record in edit mode. Just right-click the field, hover the mouse cursor over the Favorites option and from the submenu select the desired value. It will be copied to the field directly and will overwrite any previously entered value in that field.
The Favorites option (as well as the Manage favorites option beneath it) is only present if one or more favorites have already been stored for the field.
The Manage favorites option can be used to do just that: manage the favorites for the current field.
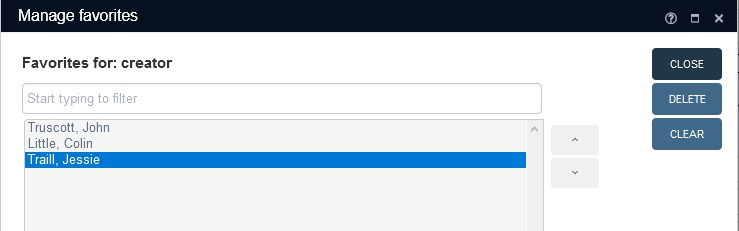
| • | To change the order of the values in the list, select one and use the arrow buttons next to the list to move the value up or down. |
| • | To view a very long value that disappears behind the right side of the list box, in its entirety, just hover the mouse cursor over the value: a tooltip will show the entire value. |
| • | If the list is long you can use the Start typing to filter box to find the value you are looking for: just type any part of the value to narrow down the visible part of the list. |
| • | Clear empties the list completely, so you can start fresh all over. |
| • | Delete removes the selected value from the list. |
| • | Close closes this window. |
2021-03-13: running an import job with non-unique locations
Suppose you'd like to import new (or update existing) object records with a new current or default location. You can use the Collections import functionality for such a job, although it must be said that updating the current location in existing records via an import job won't move the existing current location to the location history, so the location history won't be updated like it will when you use the Change locations task in Collections. However, a bigger problem arises when the imported locations (whether it be in new records or when updating existing records) have names which are not unique, like shelf 1, shelf 2, etc. while each different shelf 1 location is of course unique in actuality and also has a unique barcode.
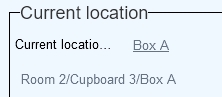
Prior to 1.11 you couldn't import such non-unique location names and hope to end up with all correct links from the object record to the proper location record. But that has changed in Collections 1.11. A requirement is that an appropriate location context field is present in your application. Such context fields are usually non-labelled, read-only fields underneath the Normal location and Current location fields in object or archive records, which display the entire upwards location hierarchy for the current or normal location, up to and including the location or container name itself, like Room 1/Upright 3/Shelf A for example, while the linked location is just Shelf A. A second requirement is that any new location you wish to import (and overwrite Shelf A in this example if your import is an update import) must already exist in the Locations and containers data source, as well as it upper hierarchy. So suppose a new location hierarchy is Room 2/Upright 2/Shelf C, then records for these three locations must already exist and be hierarchically linked.
Now when you put together your import job for object records, the only field and value you need to import as far as the current or normal location is concerned, is not the linked location field itself (like location.default.name or current_location.name) nor the location name, but the associated location context field instead, like location.default.context or current_location.context with the target full location context string up to and including the location or container name itself as the value. So besides any other fields to import, like an object number for example, the imported .csv file would need to contain a column named location.default.context or current_location.context, and a new location value for an imported record would have to be a full string like "Room 2/Upright 2/Shelf C" for example. Shelf C would then automatically end up in the relevant linked location field, linking to the correct Shelf C record, namely the one hierarchically linked to the Upright 2 record (linking in turn to the Room 2 record). So if multiple Shelf C records would exist, this way of importing would ensure that always the correct one would be linked. (Note that the full location context string won't actually be stored in the location context field as the contents of such fields is always put together dynamically by the software when the record is retrieved for display or printing etc.)
If an imported context string cannot be resolved (meaning that the relevant hierarchy does not exist in the Locations and containers data source) you'll get an appropriate error and the record won't be imported/updated.
2021-03-12: SAML and OpenID Connect support in Collections: optional single sign-on functionality
Using the user authentication services of an external so-called identity provider like Azure Active Directory, Collections applications can now be set up for single sign-on functionality, using the SAML standard (Security Assertion Markup Language) or OpenID Connect (OIDC) authentication layer: single sign-on functionality allows you, as a user, to open your Collections application without having to log in explicitly via your Active Directory user name and password, if you're already logged into a different online application (using the same identity provider) in the same browser. Single sign-on is an attractive option if your organisation already employs an external authentication service for other online tools as it helps to log in quickly into all of those tools, without security risks.
The use of external authentication services is not included in your Axiell license and setup of this functionality is complex, so please consult the Axiell ALM Sales department for more information.
2021-03-10: a distinction between indexed and non-indexed fields for searching and sorting
Although you can perform an advanced search on both indexed and non-indexed fields, searching on indexed fields is much faster. So before you execute an advanced search it would be good to know if you can expect a quick search result (because you're only searching on indexed fields) or a possibly lengthy one (because at least one the fields you are searching on is a non-indexed field).
In the Fields list on the Advanced search tab you'll normally only see indexed fields, but the list will also show non-indexed fields if that option has been switched on via the Settings button in this window. If that is the case, Collections 1.11 will show all indexed fields in bold type, while all non-indexed fields have a lighter font colour plus the explicit "(Not indexed)" indication behind the field name: the list of non-indexed fields starts after the list of indexed fields.

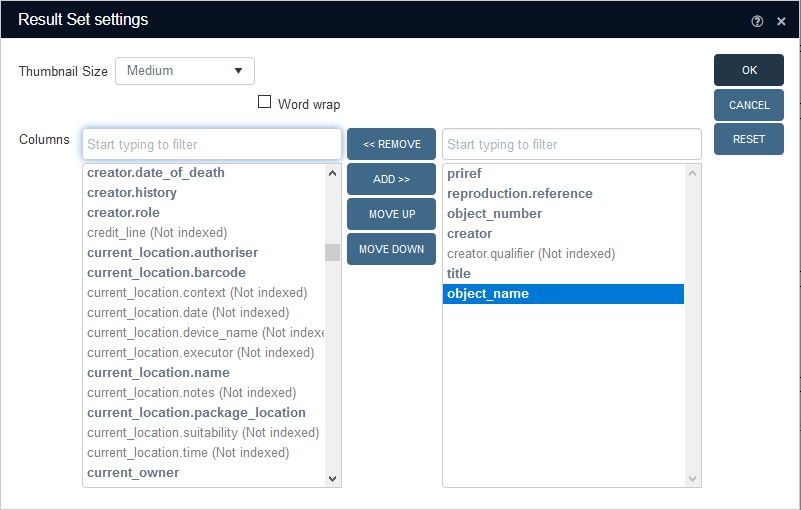
In the Result set settings window (which can be opened via the Settings icon in the Result set context toolbar) you determine which columns will be displayed in the Result set. You may include both indexed as well as non-indexed fields, although you won't be able to sort the Result set on non-indexed fields. To make the distinction between both types of fields clearer, here too the indexed fields are now displayed in a bold font type while the non-indexed fields are marked "(Not indexed)" and displayed in a lighter font colour.
2021-03-09: optional great performance increase for records with many links
If you have records with hundreds or thousands of reverse or hierarchical links to other records, like a loan record with many links to object records, or archive records with many child records for example, then opening, editing and saving such a record can take a very long time. To solve that problem, a new, optional SQL table structure has been designed, especially for heavily used linked fields. If implemented in your databases by your application manager or by Axiell ALM, this will lead to a great improvement in performance when it comes to processing such records. See the Designer Help topic for more information about how to implement this.
2021-03-08: partial clean-up of Related records view

As you may know, the optional Related records view provides an alternate overview of all linked records in one or more linked fields, grouped per linked data source, whilst in the linked data sources it provides an overview of all records in the first mentioned data source linking to the current record.
Previously, when you had used this view to jump to a record in another data source and you were about to navigate back to the record you came from, you sometimes had to choose which data source to return to. For example, the original record may have been listed underneath the Internal object catalogue as well as underneath the Objects data source. Whichever you chose, you'd end up in the same record but in the context (available screen tabs) of the selected data source, which could have been relevant for your next search or because you may have different access rights in different data sources.

In Collections 1.11 this behaviour has changed, but for reversely linked fields only. When you're about to navigate back to the original record, you will never have a choice of different data sources associated with the linked database again. The only data source you'll be allowed to jump "back" to is the data source which is associated with the dataset with the narrowest record number range in the linked database applicable to the relevant record number. For example, if you jump from a book record to a linked object record, then jumping back now always means opening the book record in the Books data source. You won't have the choice to open it in the larger Library catalogue data source anymore. However, that also means that if you had opened the book record from within the Library catalogue in the first place before you jumped to the linked object record, you won't be able to jump back to the book record within the Library catalogue context.
Note that the fixed text for a related data source (like Library catalogue in the attached screenshot) may not indicate the name of the real target data source because for reversely linked fields that text is fixed per linked field and it applies to all relevant data sources. For single-sided linked fields though, it's possible that the related record link from within the linked-to database does include the proper target data source if set up that way:
![]()
For single-sided linked fields (like most fields linking from a catalogue to the Thesaurus or Persons and institutions), the Related records view from within the data source without linked field (like the Thesaurus or Persons and institutions) still shows all data sources to jump to instead of only the most specific ones, although they do jump to the most specific one.
2021-03-08: purging saved searches
When a lot of saved searches are always being created but never really cleaned up, it will become harder to find the saved search you are looking for and even harder to decide which saved searches have become obsolete if at some point a clean-up is planned at last.
To solve this problem, Collections administrators (users with the $ADMIN role in the application definition) now have the option to purge (delete) obsolete saved searches in a clever and efficient way. From Collections 1.11 you'll find a Purge button in the Manage saved searches window (which can be opened via the shopping cart icon in the Result set context toolbar):

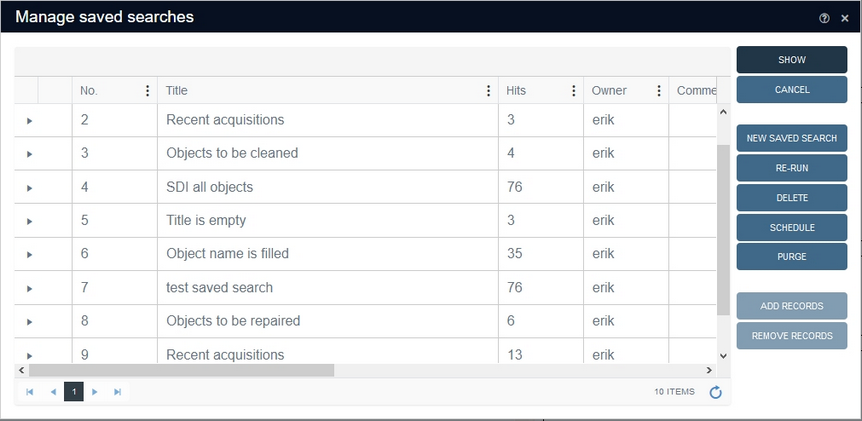
When you scroll the list of saved searches all the way to the right, you'll see three columns, showing the Modification date (the date on which the saved search was rerun or edited in some way), the Creation date (the date on which the saved search was first created) and the new Last retrieved date which represents the date and time on which the saved search was last shown in the Result set. The latter date is only set when a saved search is opened with Collections 1.11 or higher, so at first you'll notice that this column is empty and only fills up slowly as saved searches are retrieved by users. You can sort on any column by clicking its header repeatedly or by selecting a sort or filter option via the vertical ellipsis icon in the column header. You don't need to do any sorting or filtering before you start purging, but it is useful for deciding which of the three columns and which date to use for purging.
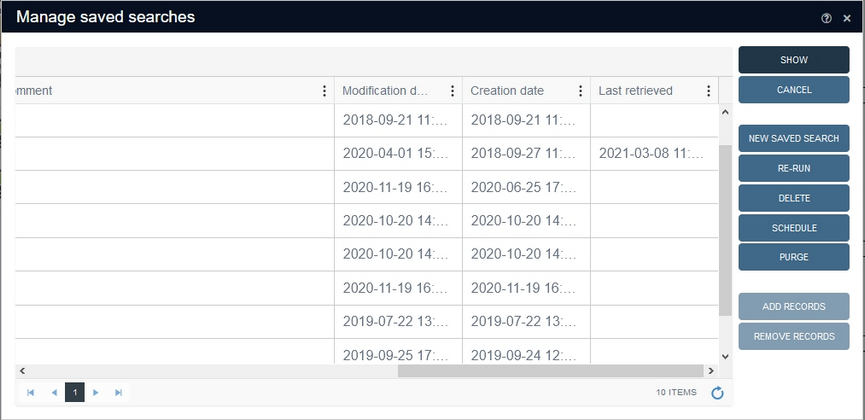
Click the Purge button to open the Purge saved searches dialog. First choose if you'd like to purge on created, last retrieved or modified date by selecting the option from the when drop-down list. Then select the desired before date by clicking the calendar icon or typing the date yourself. Then click OK.
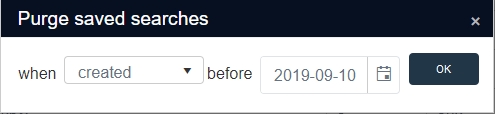
You'll still get a confirmation message, telling you how many saved searches will actually be deleted. (Note that the deletion only deletes the saved searches, not the referenced records themselves.) Click Yes to start the deletion.

2021-02-24: Export to Excel or CSV now exports the current language value of an enumerated field
In Collections, drop-down lists (enumerative fields) display values in your currently set interface language, but the actually stored value is a language-independent "neutral" value which might not be human-readable.
You usually don't have to deal with that neutral value, but until now, the Export to Excel and Export > CSV functions did export that neutral value of any enumerated field.


However, from Collections 1.11, the value in the currently set interface language will be exported, instead of the neutral value, providing a more user-friendly output file.
Do note that interface-dependent enumerated field values cannot be imported from such CSV files anymore, because any import with Collections, Designer or import.exe requires the neutral values.
2021-02-22: Copy record and Record template functions availability
By default, the Copy record and Record template functions in the Record details context toolbar have always (well, since they were introduced) been available in all data sources and there was no way to hide these functions.
![]()
![]()
From Collections 1.11 though, these functions may be hidden in all or some data sources for all or just certain users. See the relevant Designer Help topic for more information about that.