Notes de version 1.6

Contents
2019-08-22 : version 1.6 d'Axiell Collections
Nous vous proposons aujourd'hui la sixième mise à jour d'Axiell Collections 1, et allons vous donner un aperçu de ses nouvelles fonctionnalités.
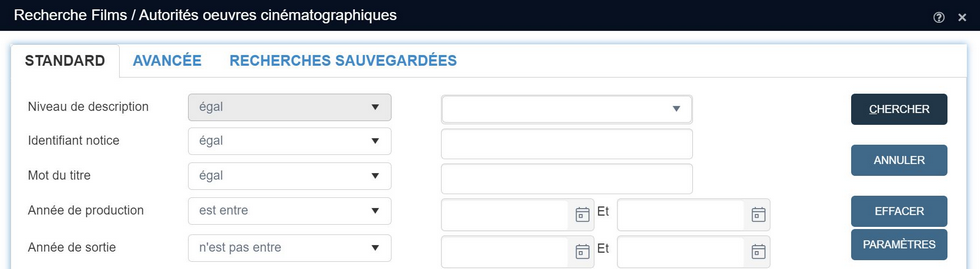
2019-08-15 : la recherche utilisant des dates, dates ISO, nombres entiers et index numériques avec "est compris entre"
L'onglet de recherche Standard de la fenêtre Recherche <source de données> inclut dorénavant les opérateurs est compris entre et n'est pas compris entre pour ce qui concerne les points d'accès utilisant des dates, dates ISO, nombres entiers et index numériques. A partir du moment où l'on sélectionne l'un de ces opérateurs, une nouvelle zone de saisie s'affiche à la suite de la zone de saisie déjà en place, pour vous permettre d'effectuer une recherche portant sur un intervalle de dates ou sur un intervalle de nombres (ou de numéros, quand il s'agit d'une numérotation), compris entre deux repères donnés. Notez que la recherche inclut les dates et nombres saisis, ce qui implique que, si votre recherche porte sur les numéros de notice compris entre 100 et 200, les notices dont le numéro est 100 et 200 pourront faire partie du résultat. Cela implique également que, si votre recherche porte sur les numéros de notice qui ne sont pas compris entre 100 et 200, les notices dont le numéro est 100 ou 200 ne pourront pas faire partie du résultat.
2019-08-08 : export de l'ensemble des occurrences de champ au format CSV
Quand il s'agissait de champs répétables, l'export au format CSV ne s'appliquait jusqu'ici qu'à la première occurrence du champ. A partir de la version 1.6 d'Axiell Collections, vous avez la possibilité de choisir entre export du contenu du premier champ et export du contenu de tous les champs. Le fichier CSV ayant autant de colonnes qu'il y a de champs exportés, les différentes occurrences d'un champ répétable sont concaténées et distinguées les unes des autres par un séparateur qu'il est possible de choisir dans la colonne du champ concerné.
Toutes les options d'export au format CSV se trouvent dans la boîte de dialogue Paramètres CSV. Pour commencer, il faut cliquer sur l'icône Export après avoir procédé à la sélection de notices dans la Liste résultat.

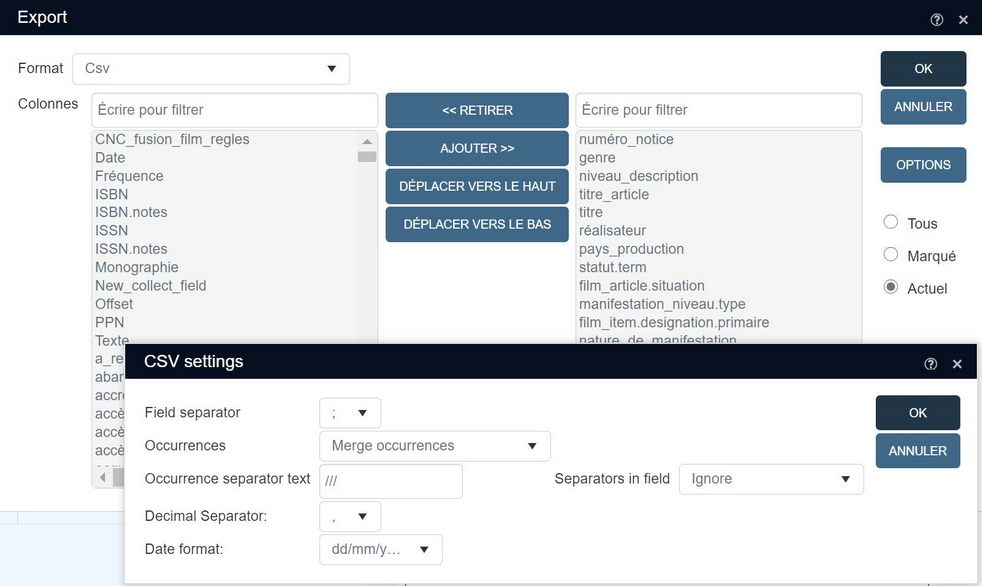
Choisissez le format Csv, faites la sélection des champs à exporter, précisez quel est l'ensemble de notices concerné : Tous, Marqué ou Actuel, puis servez vous de la touche Options pour ouvrir la boîte de dialogue CSV settings. Les options proposées sont les suivantes :
| • | Séparateur de champ - c'est à vous de choisir si les colonnes correspondant à chaque champ vont être séparées par une virgule ou par un point-virgule dans fichier CSV. Vous n'avez pas à vous inquiéter des virgules ou points-virgules faisant éventuellement partie de vos données car ceux-ci seront de toute façon mis entre guillemets. Ces deux séparateurs de champ sont acceptés dans Excel, mais on ne peut savoir à l'avance lequel des deux permet un affichage correct au format CSV (avec une colonne par champ dans la feuille de classeur) : cela peut en effet varier d'une installation Windows à l'autre, il faut donc faire des essais pour savoir dans quel contexte on se trouve. Sinon, la virgule et le point-virgule sont des séparateurs de champ au rôle équivalent. |
| • | Occurrences - il faut sélectionner soit Première occurrence, soit Fusion des occurrences. Fusion des occurrences concatène toutes les occurrences of a field d'un champ et les sépare les unes des autres avec le Caractères séparateurs d'occurrences. Cette option s'appliquant à tous les champs qui font l'objet d'un export, le traitement des données est le même pour tous les groupes de champs répétables. |
| • | Caractères séparateurs d'occurrences - on saisit ici les caractères (il peut y en avoir un ou plusieurs) qui sont utilisées pour séparer les occurrences de champ les unes des autres. Dans ce contexte, il vaut mieux opter pour un ou des caractères peu susceptibles d'apparaître dans les données à exporter. Au moment de l'export, les champs non remplis seront traités de la même façon que les champs ayant un contenu, avec les mêmes séparateurs de champ. |
| • | Séparateurs présents dans les données - même si les Caractères séparateurs d'occurrences que vous prévoyez d'utiliser sont peu susceptibles d'apparaître dans les données à exporter, il vaut mieux parer à toute éventualité. C'est pourquoi, si le cas venait à se produire, trois façons de réagir vous sont proposées : - Erreur (option recommandée) suspend l'export et envoie un message d'erreur; - Ignorer laisse l'export suivre son cours, mais sans qu'il y ait moyen de discerner quand des caractères correspondant aux caractères séparateurs sont présents parmi les données concaténées, si ceux-ci font partie des données ou remplissent le rôle de séparateurs entre deux champs; - Extraire de la notice intervient en extrayant des données les caractéres correspondant aux caractères séparateurs à chaque fois qu'il les rencontre (mais sans les extraire effectivement, bien entendu), pour leur faire remplir le rôle de séparateurs entre deux champs, ce qui peut avoir pour conséquence que les données après export ne soient pas tout à fait identiques aux données avant export (toutefois, si l'on a bien choisi les caractères séparateurs, cela devrait être d'un impact très limité). |
2019-08-08 : dérivation de notices appartenant à une autre source de données
Il peut être utile de déplacer des notices, ou d'en faire une copie, depuis une source de données vers une autre qui présente des similitudes avec elle, par exemple depuis le Catalogue des oeuvres cinématographiques vers le Catalogage des affiches. La fonctionnalité de dérivation permet de remplir cet objectif. Si des dérivations sont possibles dans le contexte d'une source de données définie, on peut voir figurer dans la barre d'outils contextuelle de la Liste résultat une icône symbolisant la dérivation. L'info-bulle qui apparaît quand on survole l'icône à l'aide de la souris précise dans quel sens peut s'effectuer la dérivation : elle permet de copier-coller ou de couper-coller une ou plusieurs notices à partir de la source de données dans laquelle on se trouve vers une autre source de données.
Cliquez sur l'icône pour effectuer la recherche des notices qui sont à dériver d'une source de données à l'autre. Dans le résultat de recherche, il suffit de marquer les notices à dériver et de cliquer sur OK. Pour ce qui est de la source de données dans laquelle doit se faire la recherche, comme des notices qui doivent être déplacées ou copiées, ou bien des champs qui sont concernés, c'est le paramétrage de la fonctionnalité dans le contexte de la source de données qui permet d'en décider.
2019-08-05 : impression d'étiquette et de code-barres/QR code par l'intermédiaire de modèle Word
Auparavant, l'impression d'un code-barres par l'intermédiaire d'un modèle Word impliquait l'installation sur le PC d'une police de caractères spécifique. Depuis la version 1.6 d'Axiell Collections, ce n'est plus nécessaire : il est désormais possible d'indiquer au sein du modèle Word le type de codes-barres qui doit être imprimé, et quelle en est la longueur. La syntaxe permettant de donner le format d'un code-barres est la suivante :
<<field_tag[occurrence].barcode_type|width=width_in_pixels|height=height_in_pixels>>
Les codes-barres et QR codes disponibles sont les suivants :
| • | code39 |
| • | code93 |
| • | code128 |
| • | ean8 |
| • | ean13 |
| • | qrcode |
| • | upca |
Notez que EAN-8, EAN-13 and UPC-A suivent des règles strictes. Si un code-barres ne respecte pas ces règles, il ne peut être imprimé.
Pour un code-barres, il faut toujours définir une largeur et une hauteur, tandis que pour un QR code, il suffit d'une dimension. Il faut faire des essais avec les dimensions pour faire en sorte qu'un code-barres de la longueur maximale peut s'intégrer au type d'étiquette ou au type de feuille que l'on compte utiliser. On doit aussi vérifier que les lecteurs de code-barres dont on dispose sont à même de lire les codes-barres générés.
Exemples :
<<ba[1].code39|width=270|height=77>>
<<Nn[1].code128|width=300|height=100>>
Impression de l'étiquette
La taille d'une étiquette imprimée à l'aide d'un modèle Word est en général réduite aux dimensions de la cellule de tableau qui la contient. Si l'on n'emploie pas de tableau, la taille de l'étiquette imprimée est sa taille d'origine. Depuis la version 1.6 d'Axiell Collections, la syntaxe employée permet de définir la taille d'une étiquette à l'aide de sa longueur. (c'est le seul mode d'intervention possible, étant donné que les modèles d'étiquettes constituent un grand tableau dont les cellules ne peuvent contenir de tableau imbriqué.) Il n'y a pas de hauteur à définir pour que les proportions soient correctes (aussi n'est-il pas possible de définir une hauteur sans définir de largeur). La définition d'un format pour le code-barres se présente sous la forme suivante :
<<field_tag[occurrence].thumbnail|width=width_in_pixels>>
Exemple :
<<FN[1].thumbnail|width=270>>
Notez que l'étiquette est d'abord utilisée dans son format d'origine, et n'est redimensionnée qu'au moment de l'impression, si bien que le paramétrage s'appliquant aux étiquettes n'a aucun impact sur la performance.