ImportTool

Contents
The indexed link and full text index types, the triple index type for reverse relation metadata and the metadata database themselves are supported by all Axiell software, but importing new data into databases with these table types can only be done either through Axiell Collections, through the internally used Axiell Migration tool or via importtool.exe. Axiell Designer and import.exe (which normally allow for more complex import jobs than Collections) however, are not capable of such imports and probably won’t ever be as they will be deprecated in favour of importtool.exe. Importtool.exe has been developed to support all current database table types used by Collections and to thereby replace Designer and import.exe for the more complex import jobs.
The import jobs themselves can still be made in Designer, but not all options are supported in importtool.exe and the field mapping for XML exchange file types is different. It does support the following features:
| • | ASCII Delimited (CSV)*, unstructured AdlibXML, grouped AdlibXML and (Adlib) Tagged import; |
| • | Process links and Process internal links options (on or off); |
| • | Import-adapl scripts - a storage adapl for the .inf is not executed; |
| • | Clear database prior to running the import job (on or off); |
| • | The Always create new domain records import job option is supported from version 7.12.1.6395. Mark the Always create new domain records checkbox in the import job to make sure that whenever an existing term is imported into a linked field with a domain different from the domain(s) for the already present term record, a new linked record will be created for that term, with the new associated domain. For an existing term without domain, the imported term will also be stored in a new record. |
| • | Setting the default Record owner value; |
| • | The Add new records option (on or off); |
| • | Updating existing records (when Update tag has been filled in), but the Update language option is not used and the Delete data in existing records option is not checked, it is implicitly set to No; |
| • | Multilingual grouped AdlibXML and multilingual unstructured AdlibXML can be imported (not any deviating XML types): use the -x command-line argument to select either one. For an update job you can provide the “culture” (data language) in the command line if the data language of the imported field data to search for in the update tag is different from the Windows locale, otherwise the Windows locale of the environment in which importtool is running will be used. (The Update language option in import jobs isn't used.) See the list below for the relevant command line option; |
| • | For unstructured AdlibXML only (not grouped) a mapping of fields to import can be specified in the import job (from version 7.13.1.6881). However, where Designer required full XML paths in the Source field column on the Mapping tab of an import job, importtool.exe only allows field names in this column (without any path in front of them or any sharp brackets). Since this is only for unstructured AdlibXML import, you will have to add the -x Unstructured argument to the command-line options when executing ImportTool. For matching field names you can use the ** | ** mapping. At first, all field and group names in the source file needed to be identical to the destination fields and field groups, but from version 7.14.1.7390 this is not a requirement any more, so the source AdlibXML file may contain deviating field and group names. |
| • | Changing the default tag separator using the <FS> field mapping option; |
| • | Changing the default record separator using the <RS> field mapping option; |
| • | Milestone value set in import job; |
| • | You can use temporary tags via the PARAMETERS FACS buffer: see the section below for more information. |
The Forcing always allowed option is implicitly switched on by default, like in Collections import. The Ignore priref checkbox is assumed to be deselected. Options not mentioned here, are ignored by the import tool.
Remember that after creating the import job in Designer, you should not run it from Designer if your database contains the new types of indexes: then always use the tool.
The command line syntax of this tool is:
Importtool.exe -p <path to import job folder> -i <name of import job> -l <optional path to log file>
Complete list of command-line arguments:
Argument |
Alternative argument |
Optional / Mandatory |
Description |
-c |
--culture |
optional |
Culture (data language) of multilingual field data to use for searching the update tag, e.g. -c "en-US" or --culture "en-US". This option is available from version 7.12.1.6159. By default, en-US is assumed. |
-i |
--import-job |
mandatory |
Name of import job file, without path. |
-n |
--new-records |
optional |
Flag to indicate that only new records should be imported. |
|
--noheader |
optional |
If a field mapping is present in the import job, specifying --noheader on the command-line means that your source CSV file should not contain a field names header row (so all rows will be imported). If a field mapping is present in the import job and you leave out the --noheader command-line option, it is assumed there's a field names header row in the CSV file and those will then be used as the target fields (instead of the Destination fields in the import job). |
-p |
--path= |
optional |
Path to the import job file folder: enclose it in double quotes if the path contains spaces. If no path is provided, the import job file should be present in the current importtool.exe folder. |
-l |
--log-file= |
optional |
Path to optional log file: include the desired log file name in the path, e.g. mylog.txt. |
-x |
--xml-type= |
optional |
Switch for the source XML type: Grouped or Unstructured. Note that for unstructured XML you will have to keep track of the occurrences of fields that are in a group to keep the correct data together. Grouped is the default |
--help |
optional |
Display this list of arguments. |
|
--version |
optional |
Display version information about importtool.exe. |
* Note that to import a CSV file with importtool.exe you must provide the field mapping in at least either the CSV file or the import job and possibly use the --noheader command-line argument to specify which to use. In the CSV file you specify this by making sure its first row contains the English field names (of the target fields) pertaining to their columns (just like a CSV for Collections import requires). In case of an update import, all occurrences of those target fields in the updated record will be emptied and new occurrences will be imported.
The other way is by providing the field mapping in the import job itself. This allows you to set an Update option per field. Make sure all columns are mapped. (Mapping a single source field to multiple destination fields is supported from version 7.14.1.7450.)
From importtool.exe 7.13.1.6895, multilingual (Adlib) Tagged and CSV (where a column contains values in a single language of a field and multiple columns should be mapped to a single multilingual target field) you can use the Language property per field in the field mapping in the import job to indicate into which language in the target field the values from the relevant column should be imported.
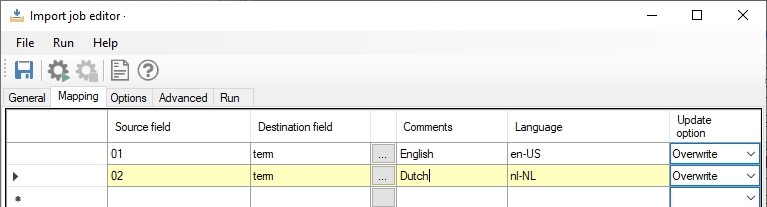
You could omit the Language for your default language though and specify this language in the Default language property in the import job instead. The Make this the invariant language checkbox for this Default language is supported too. Use a recent build of Designer to be able to set these properties successfully in the import job.
See The Import tool: create and update records (axiell.com) for more information about the CSV requirements (with a first row of field names).
Using temporary tags in an import job and adapl
When running imports it is sometimes useful to map fields to temporary (dummy) fields that can be processed further in the import adapl without the need to create those fields in the data dictionary of the target database definition first.
From ImportTool version 7.13.1.6935, this has been implemented for (Adlib) Tagged and CSV import jobs via the PARAMETERS FACS construction (as was already available for Collections tasks and output formats).
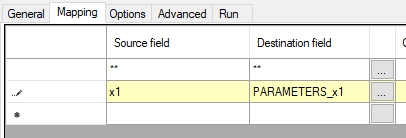
The idea is that you can add temporary field tags (preceded by the fixed string PARAMETERS_), which haven't been defined in the data dictionary, as Destination fields in the import field mapping. Then you can use those tags as variables in a standard PARAMETERS FACS declaration (which doesn't point to any .inf) in the adapl, where you can process the contents of the variable as you like before assigning the final value to an actual target field tag.
So in this example, there's a tag x1 in the source file, that is mapped to a temporary tag x1 in the PARAMETERS FACS buffer for this purpose. In the adapl you declare the PARAMETERS FACS declaration with the used temporary tags as you would do normally. Param1 in the trivial example code below is just a random alias for x1 which can be processed further (which doesn't happen in this code sample) before it is assigned to actual tag tc.
* parameters import adapl
fdstart PARAMETERS ''
x1 is param1
fdend
tc = param1 /* Put the dummy field in the term code field
end
The PARAMETERS FACS buffer is automatically cleared for each processed record from the source file.